LMCache’s New Architecture Boosts MoE Inference Performance by 10×
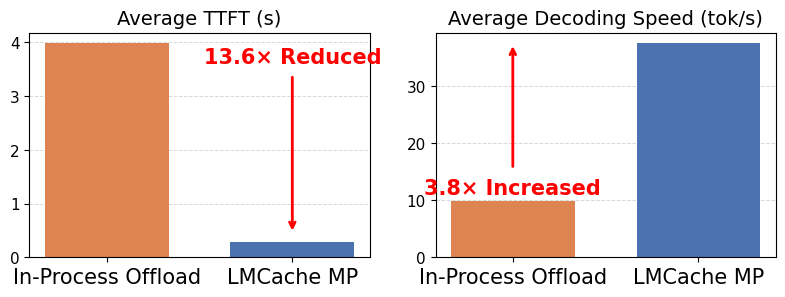
Modern LLM serving workloads are defined by strict latency requirements, high concurrency, and rapidly growing context lengths. Applications such as multi-turn chat, AI agents, and retrieval-augmented generation continuously build on prior context, leading to substantial reuse of previously computed states. In production, systems must minimize time-to-first-token (TTFT) while maintaining stable decoding throughput under heavy concurrent […]
