LMCache on Amazon SageMaker HyperPod: Accelerating LLM Inference with Managed Tiered KV Cache
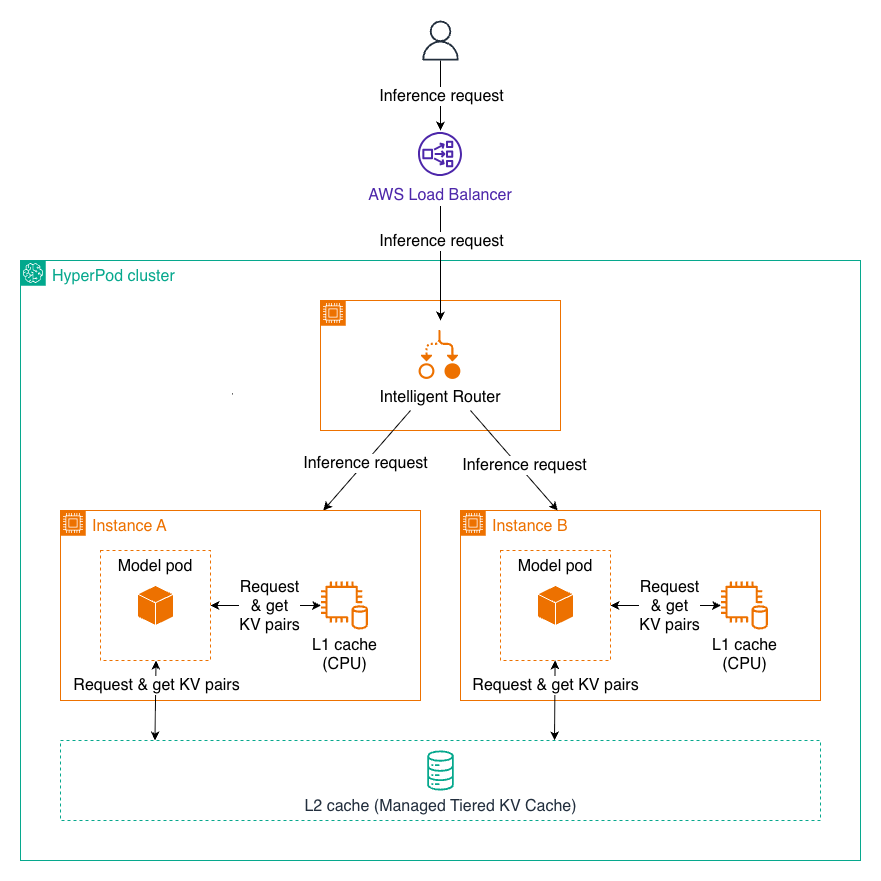
Overview Large language model (LLM) inference performance depends heavily on how efficiently the system manages key-value (KV) cache — the stored attention states that allow the model to avoid recomputing previous tokens. As context lengths grow and concurrent users increase, the KV cache can exceed GPU memory capacity, forcing expensive recomputation that degrades latency and […]
