Nvidia Dynamo + LMCache: Accelerating the Future of LLM Inference

We’re thrilled to announce that the Nvidia Dynamo project has integrated LMCache as its KV caching layer solution. This is a big milestone: Dynamo gets a battle-tested caching solution, and LMCache becomes part of a production-scale ecosystem used by many developers worldwide. Why KV Caching Matters KV caching is a foundational optimization for modern LLM […]
LMCache supports gpt-oss (20B/120B) on Day 1
LMCache now supports OpenAI’s newly released GPT-OSS models (20B and 120B parameters) from day one! This post provides a complete guide to setting up vLLM with LMCache for GPT-OSS models and demonstrates significant performance improvements through our CPU offloading capabilities. Step 1: Installing vLLM GPT OSS Version Installation Test the Installation Step 2: Install LMCache […]
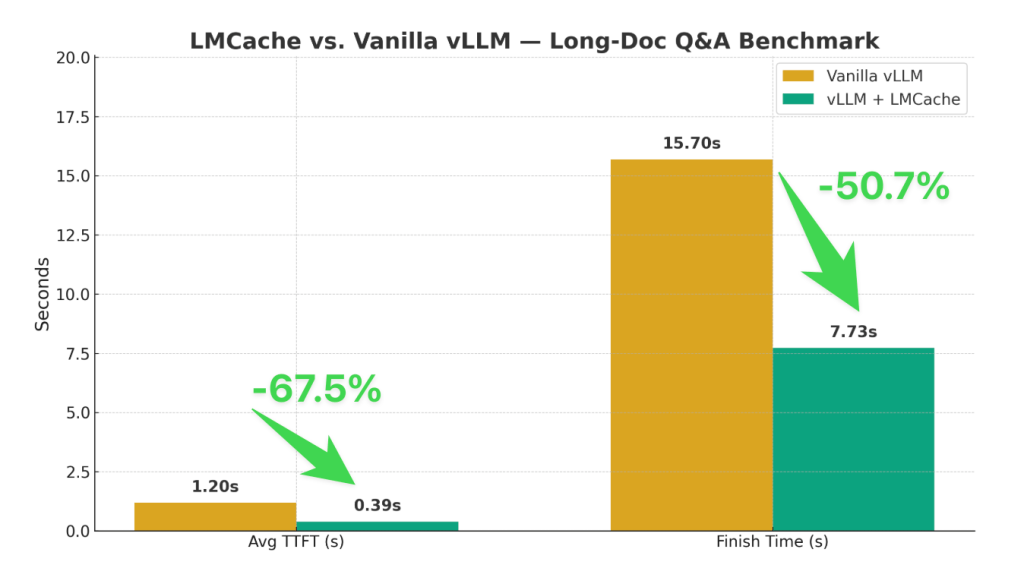
Speeding Up LLM Inference: Beyond the Inference Engine

TL;DR: LLMs are rapidly becoming the dominant workload in enterprise AI. As more applications rely on real-time generation, inference performance — measured in speed, cost, and reliability — becomes the key bottleneck. Today, the industry focuses primarily on speeding up inference engines like vLLM, SGLang, and TensorRT. But in doing so, we’re overlooking a much […]
