Stop Calling It KV Cache: It’s Something Much Bigger

For years, we have referred to one of the most critical components of modern LLM inference as a “KV cache.” That name made sense once. Today, it is increasingly misleading. What began as a small, ephemeral optimization inside a single inference pass has quietly evolved into something far more important: a first-class data object with […]
LMCache’s New Architecture Boosts MoE Inference Performance by 10×
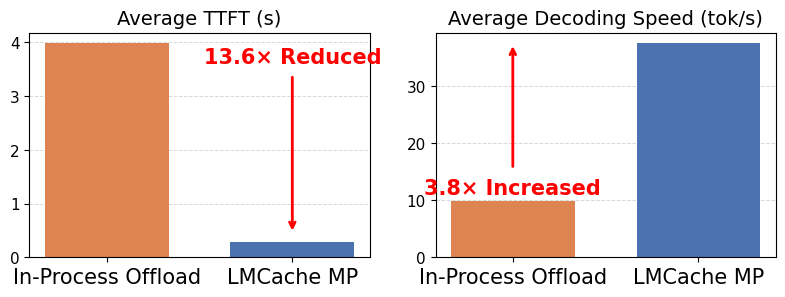
Modern LLM serving workloads are defined by strict latency requirements, high concurrency, and rapidly growing context lengths. Applications such as multi-turn chat, AI agents, and retrieval-augmented generation continuously build on prior context, leading to substantial reuse of previously computed states. In production, systems must minimize time-to-first-token (TTFT) while maintaining stable decoding throughput under heavy concurrent […]
Accelerating OpenClaw Agents with CacheBlend

The standard approach to reducing LLM inference costs is prefix caching, which reuses previously computed token states to avoid redundant computation. In practice, however, this approach misses significant caching opportunities in real-world agentic workloads! Caching in Agentic Workflows In agentic workloads, shared content (e.g., retrieved contexts and documents) frequently appears across requests at varied positions, […]
LMCache Multi-node P2P CPU Memory Sharing & Control: From Experimental Feature to Production
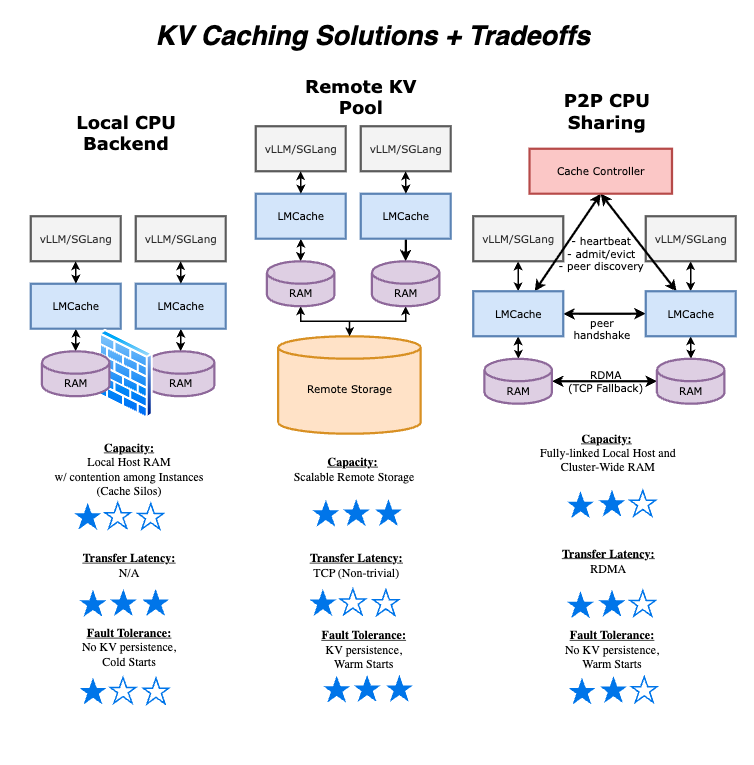
Baolong Mao (Tencent), Chunxiao Zheng (Tencent), Weishu Deng (Tensormesh), Darren Peng (Tensormesh), Samuel Shen (Tensormesh) What is P2P and what does it promise? In this blog post, we will go over: Most production vLLM deployments run multiple identical instances behind a load balancer. Each instance builds its own KV cache only from the traffic it […]
AMD × LMcache: AMD GPU Acceleration with LMcache

Introduction LLM inference becomes increasingly challenging as context length grows and workloads scale. Traditional serving engines rely on prefix-based KV cache reuse, which limits opportunities for optimization, especially when processing long, repeated, or overlapping text across different requests. LMCache addresses this challenge. It is an extension to LLM serving engines that dramatically reduces time-to-first-token (TTFT) […]
Context Engineering & Reuse Pattern Under the Hood of Claude Code
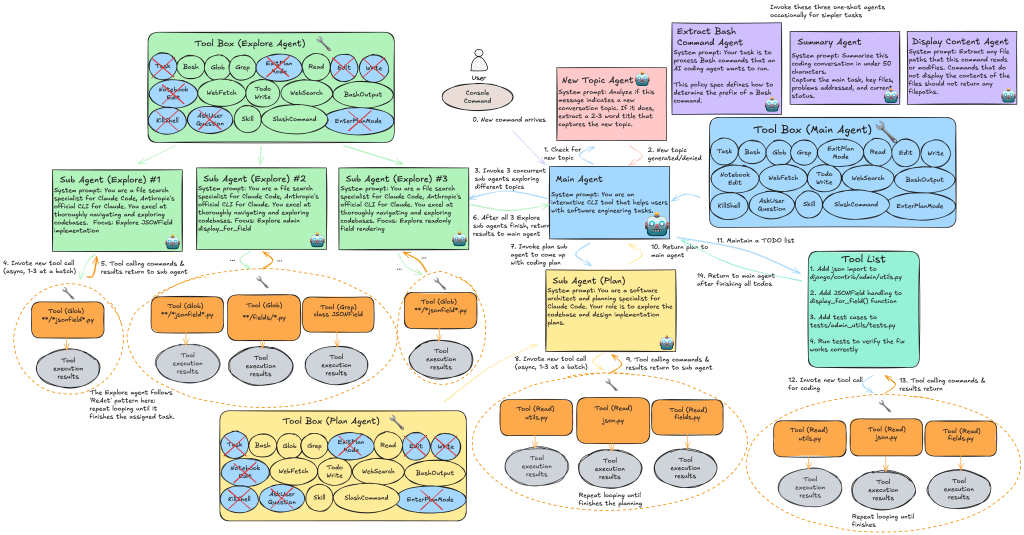
Over the last few months, Claude Code has quietly become one of the most interesting & widely-adopted real-world agentic systems available to normal developers. Unlike cloud-only agents whose internals remain hidden behind API gateways like Perplexity, Devin, or Manus, nor as fully open source agents like Mini SWE Agent or Terminus 2 where you can […]
LMCache x Ascend: Accelerating LLM inference on Ascend NPUs

Supporting Ascend NPUs We’re delighted to announce that LMCache now officially supports Ascend NPUs with the release of the LMCache-Ascend plugin. LMCache-Ascend supports a broad range of Ascend compute platforms from the cloud to the edge. This major platform expansion underscores LMCache’s commitment to delivering leading performance across a diverse hardware ecosystem, enabling developers to […]
