Deepseek V4 explained, and why it matters to your wallet
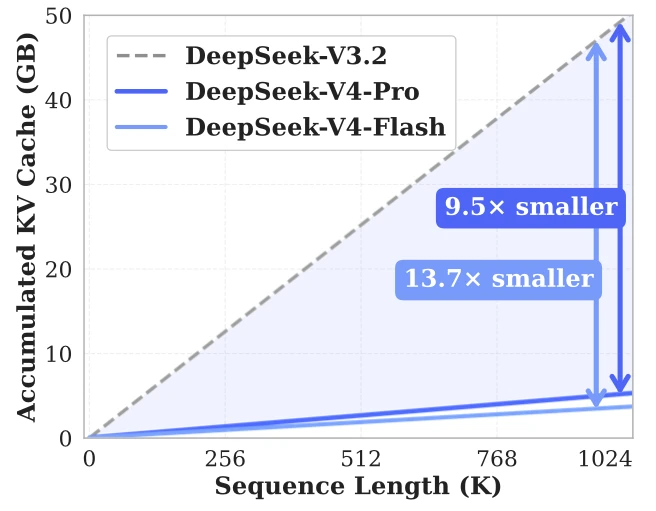
DeepSeek V4 — an open weight model that gives you the state-of-the-art intelligence, while potentially gives you much cheaper token price than its preceding model, DeepSeek V3.2. But how does DeepSeek v4 does that? Pre-requisite: attention, KV caches, and why KV cache is the key that affects token pricing To know why DeepSeek V4 can […]
What is TurboQuant and why it matters for LLM inference, in laymen’s term
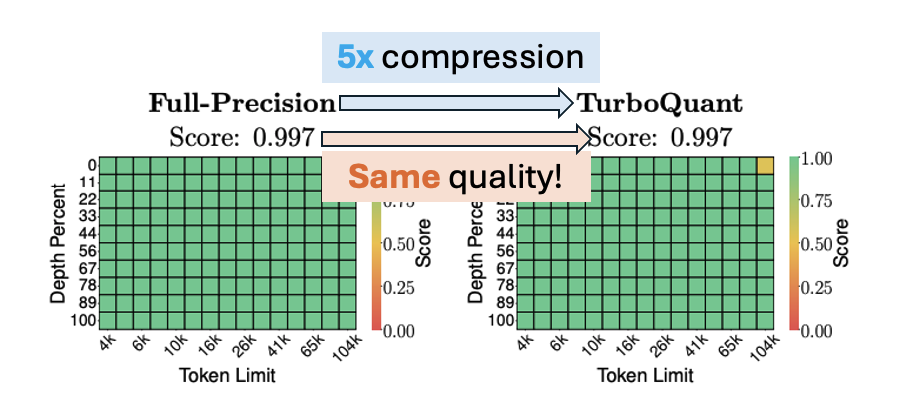
TL;DR: TurboQuant allows you to put 4x more context in your GPU without blowing up GPU memory or dropping AI’s intelligence. It does so by quantizing the memory of large language models, also known as KV cache, an important bottleneck mentioned by Jensen Huang multiple times at this year’s GTC. It relies on two secret […]
