LMCache on Amazon SageMaker HyperPod: Accelerating LLM Inference with Managed Tiered KV Cache
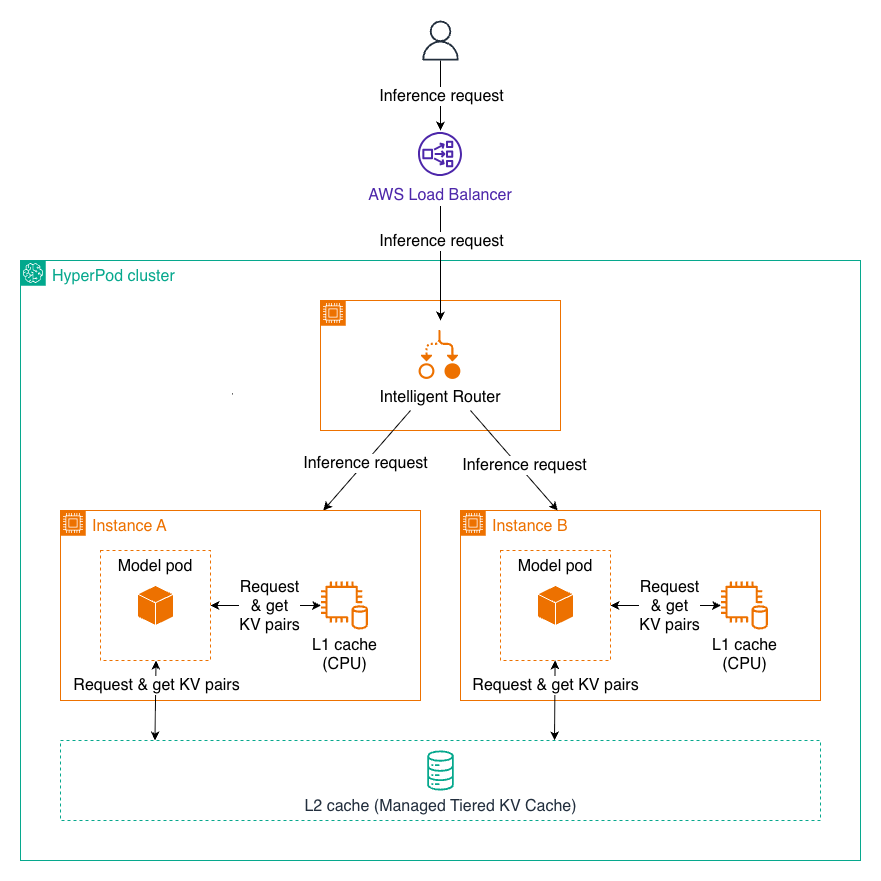
Overview Large language model (LLM) inference performance depends heavily on how efficiently the system manages key-value (KV) cache — the stored attention states that allow the model to avoid recomputing previous tokens. As context lengths grow and concurrent users increase, the KV cache can exceed GPU memory capacity, forcing expensive recomputation that degrades latency and […]
Breaking the Memory Barrier: How LMCache and CoreWeave Power Efficient LLM Inference for Cohere

The challenge: Scaling enterprise AI Enterprises today are racing to integrate large language models (LLMs) into their products and workflows, but doing it at scale brings challenges in performance, cost, and accuracy. Organizations need models to be based on their specific data, while making sure that this information remains private. Cohere, one of the leading […]
LMCache on Google Kubernetes Engine: Boosting LLM Inference Performance with KV Cache on Tiered Storage
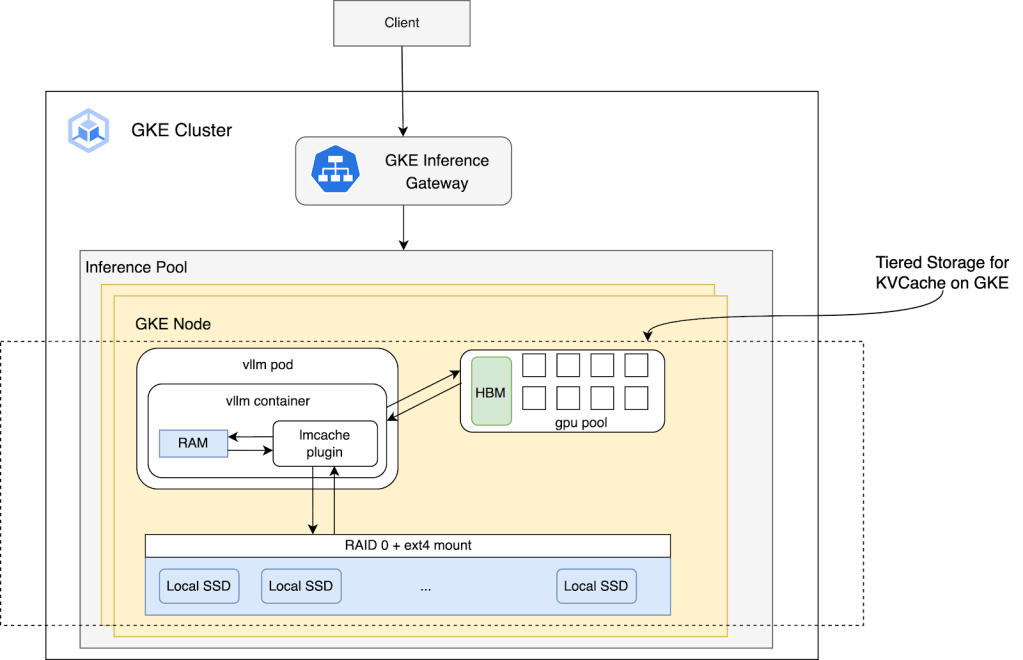
Overview of the Collaboration The KV Cache is a memory optimization that makes Large Language Models(LLMs) run the forward pass faster by storing Key (K) and Value (V) matrices to prevent the model from recalculating them for the entire text sequence with every new generated token. Maximizing the KV Cache hit rate with storage is […]
LMCache supports gpt-oss (20B/120B) on Day 1
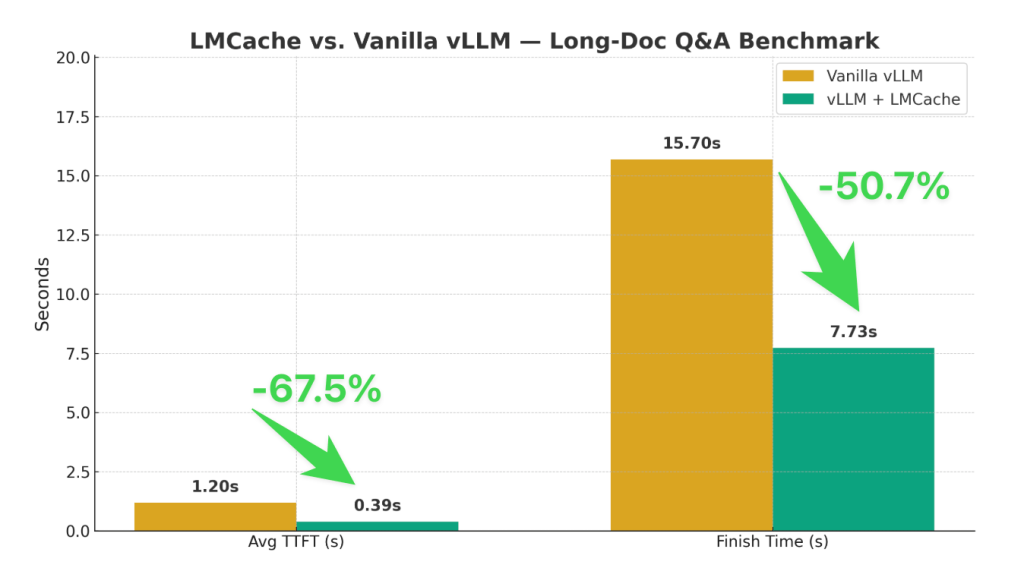
LMCache now supports OpenAI’s newly released GPT-OSS models (20B and 120B parameters) from day one! This post provides a complete guide to setting up vLLM with LMCache for GPT-OSS models and demonstrates significant performance improvements through our CPU offloading capabilities. Step 1: Installing vLLM GPT OSS Version Installation Test the Installation Step 2: Install LMCache […]
How LMCache Turbocharges Enterprise LLM Inference Frameworks
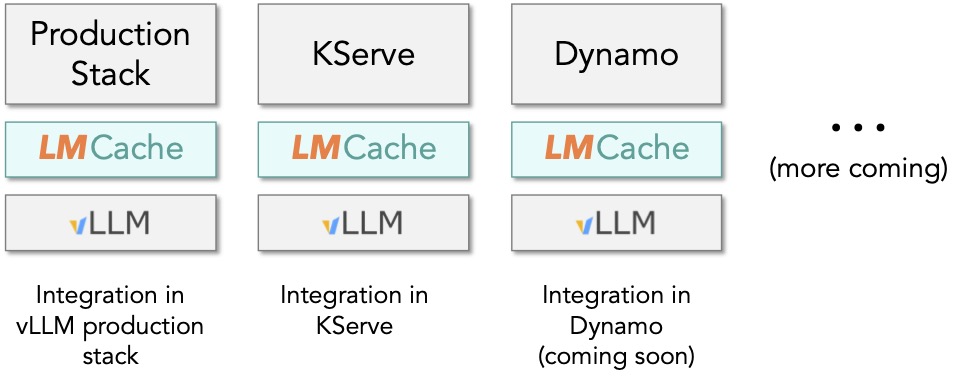
TL;DR LMCache, the state-of-the-art KV cache layer library developed by TensorMesh and the project’s open-source community, delivers breakthrough performance improvements to modern enterprise LLM inference frameworks, including the vLLM Production Stack, KServe, and NVIDIA’s Dynamo. With fast and scalable caching of long-context KV cache, LMCache helps reduce inference costs and ensures SLOs for both latency […]
