Extending LMCache Remote Connectors: MooncakeStore as an Example
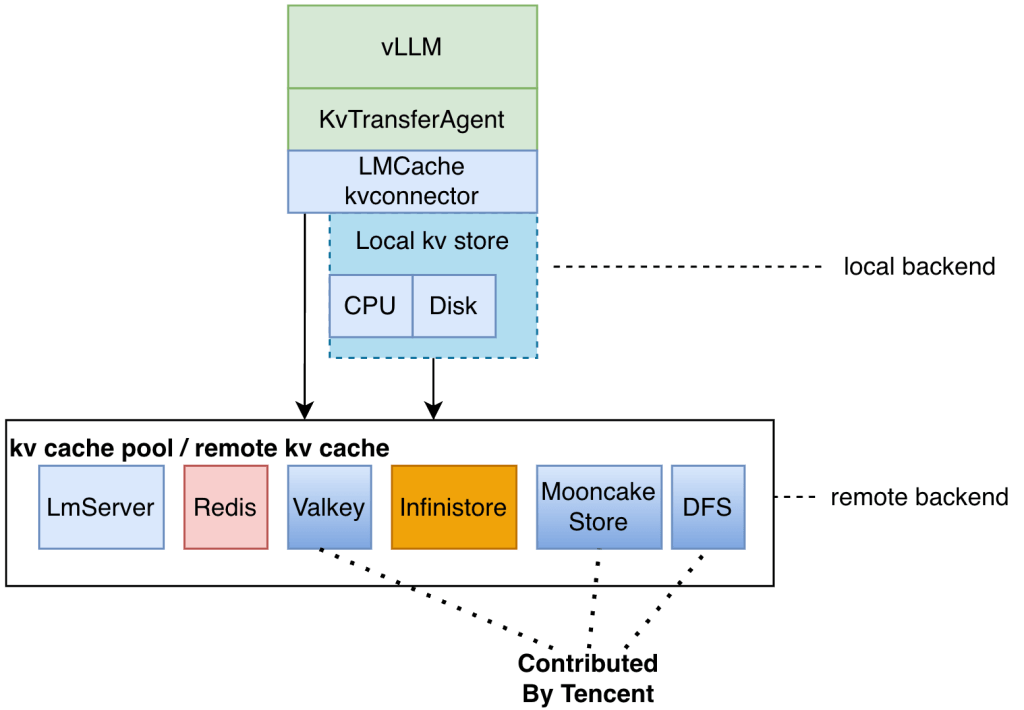
Highlights: This article refers to LMCache based on commit-01277a1 LMCache V1(experimental), and introduces it in the context of the inference engine vLLM’s V0 version. LMCache Architecture and Position in the Ecosystem LMCache is an intelligent caching middleware specifically designed for Large Language Model (LLM) inference. Here’s a breakdown of its architecture and position: In the […]
