Extending LMCache Backends: A Comprehensive Guide to Custom Backend Development
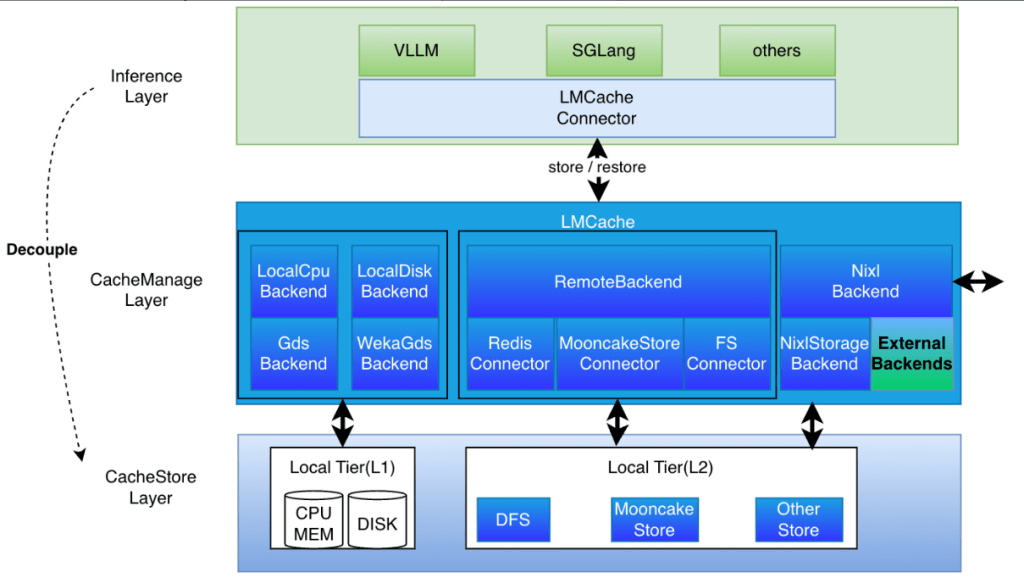
In large language model inference scenarios, the performance and flexibility of KVCache caching systems directly impact overall service efficiency. LMCache, as a high-performance large model caching framework, provides developers with rich extension capabilities through its modular backend design. This article will start with LMCache backend’s extension mechanism, using the officially provided lmc_external_log_backend as an example, […]
