LMCache + NVIDIA Dynamo 1.0: A Match Made in Inference Heaven ?

We have some exciting news to share: NVIDIA Dynamo has officially hit v1.0, and we couldn’t be more thrilled. This is a huge milestone for the LLM inference ecosystem and for us at LMCache, it’s a moment worth celebrating. What Is NVIDIA Dynamo, and Why Does It Matter? If you haven’t been following Dynamo’s journey, […]
NVIDIA Dynamo integrates LMCache, Accelerating LLM Inference

We’re thrilled to announce that Nvidia Dynamo has integrated LMCache as a KV caching layer solution. This is a big milestone: Dynamo gets a battle-tested caching solution, and LMCache becomes part of a data center-scale inference platform used by many developers worldwide to deploy AI at scale. For comprehensive details about Dynamo’s KV cache optimization […]
Nvidia Dynamo + LMCache: Accelerating the Future of LLM Inference

We’re thrilled to announce that the Nvidia Dynamo project has integrated LMCache as its KV caching layer solution. This is a big milestone: Dynamo gets a battle-tested caching solution, and LMCache becomes part of a production-scale ecosystem used by many developers worldwide. Why KV Caching Matters KV caching is a foundational optimization for modern LLM […]
Speeding Up LLM Inference: Beyond the Inference Engine

TL;DR: LLMs are rapidly becoming the dominant workload in enterprise AI. As more applications rely on real-time generation, inference performance — measured in speed, cost, and reliability — becomes the key bottleneck. Today, the industry focuses primarily on speeding up inference engines like vLLM, SGLang, and TensorRT. But in doing so, we’re overlooking a much […]
Bringing State-Of-The-Art PD Speed to vLLM v1 with LMCache
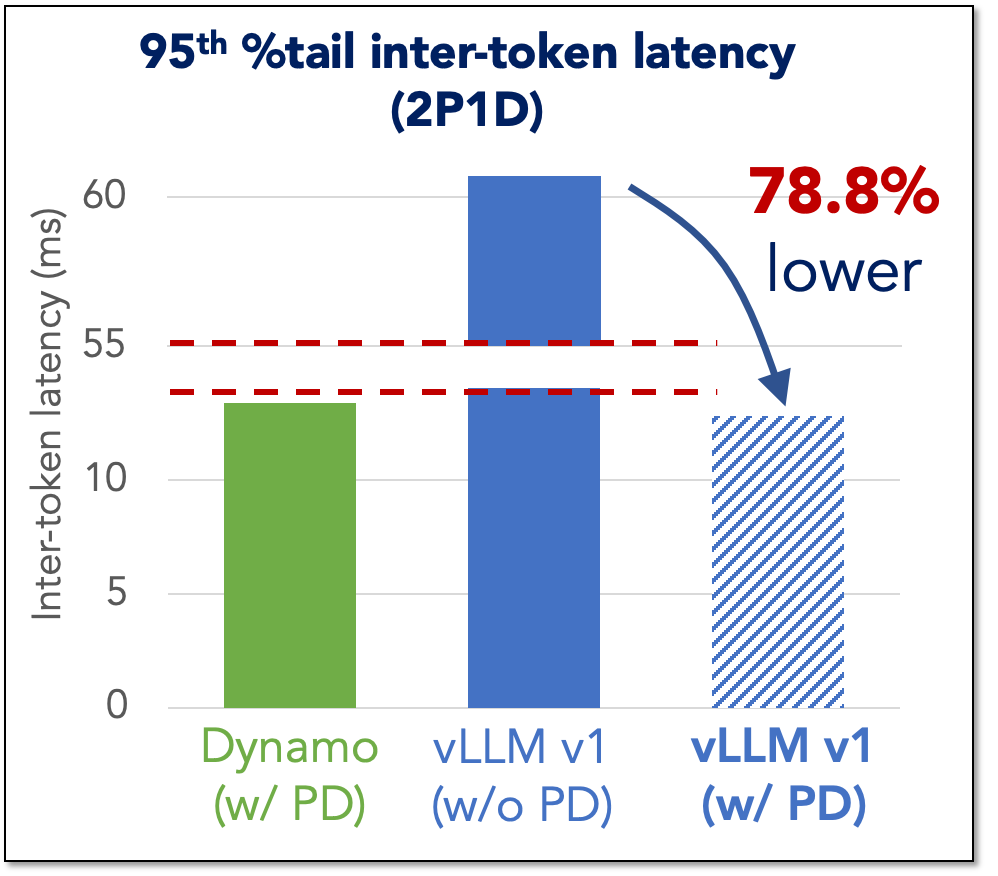
TL;DR:In our previous blog, we introduced **LMCache**’s integration with vLLM v1 and NVIDIA’s NIXL used in Dynamo, enabling Prefill-Decode Disaggregation (PD) for LLM inference. Today, we’re excited to share benchmark results that confirm this system achieves state-of-the-art PD performance, balancing time-to-first-token (TTFT) and inter-token latency (ITL) with unprecedented consistency. Here’s an example result (scroll down […]
