LMCache Extends Its Turbo-Boost to Multimodal Models in vLLM V1
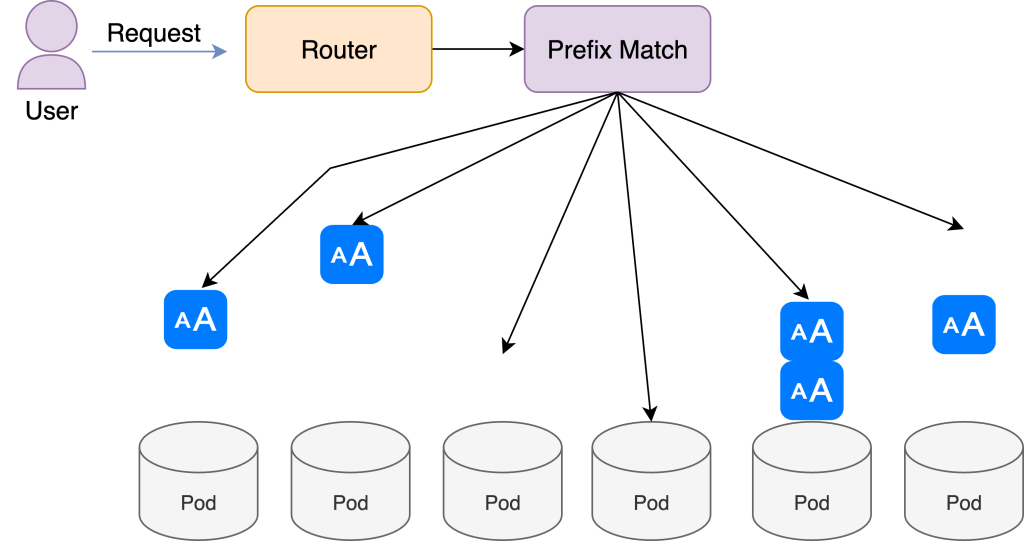
TL;DR: The latest LMCache release plugs seamlessly into vLLM’s new multimodal stack. By hashing image-side tokens (mm_hashes) and caching their key-value (KV) pairs, LMCache reuses vision embeddings across requests—slashing time-to-first-token and GPU memory for visual-LLMs. Summary — Why This Matters Multimodal large language models (MLLMs) multiply KV-cache traffic: every image can add thousands of “vision […]
