Accelerating OpenClaw Agents with CacheBlend

The standard approach to reducing LLM inference costs is prefix caching, which reuses previously computed token states to avoid redundant computation. In practice, however, this approach misses significant caching opportunities in real-world agentic workloads! Caching in Agentic Workflows In agentic workloads, shared content (e.g., retrieved contexts and documents) frequently appears across requests at varied positions, […]
Breaking the Memory Barrier: How LMCache and CoreWeave Power Efficient LLM Inference for Cohere

The challenge: Scaling enterprise AI Enterprises today are racing to integrate large language models (LLMs) into their products and workflows, but doing it at scale brings challenges in performance, cost, and accuracy. Organizations need models to be based on their specific data, while making sure that this information remains private. Cohere, one of the leading […]
How LMCache Turbocharges Enterprise LLM Inference Frameworks
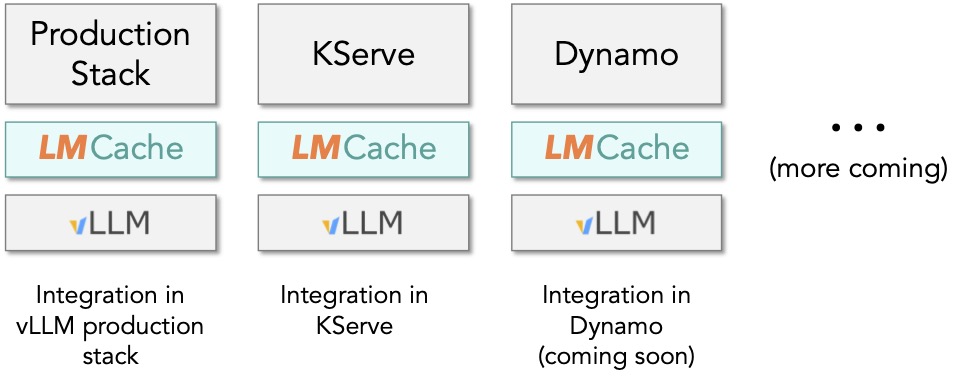
TL;DR LMCache, the state-of-the-art KV cache layer library developed by TensorMesh and the project’s open-source community, delivers breakthrough performance improvements to modern enterprise LLM inference frameworks, including the vLLM Production Stack, KServe, and NVIDIA’s Dynamo. With fast and scalable caching of long-context KV cache, LMCache helps reduce inference costs and ensures SLOs for both latency […]
CacheBlend (Best Paper @ ACM EuroSys’25): Enabling 100% KV Cache Hit Rate in RAG

Break News: “CacheBlend” Receives BEST PAPER AWARD at ACM EuroSys 2025 This week, at ACM EuroSys 2025 (Top Academic Conference in Computer Systems), Jiayi Yao, the first author of the groundbreaking paper on CacheBlend, will present our innovative work that redefines the landscape of LLM efficiency, particularly in retrieval-augmented generation (RAG) applications. This paper has […]
Beyond Prefix Caching! How LMCache Speeds Up RAG by 4.5x By One Line of Change
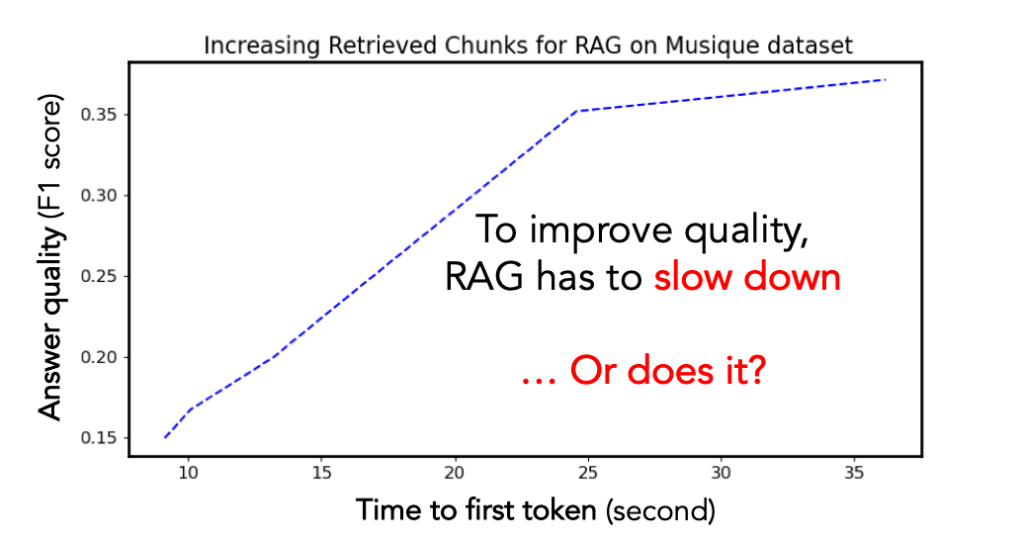
TL;DR: Your RAG can run up to 4.5× faster by pairing vLLM with LMCache . [? Source code] [? Paper] will appear in the 10th ACM EuroSys (European Conference on Computer Systems) 2025 [? 3-minute introduction video] The Problem: RAG is WAY TOO SLOW Retrieval-Augmented Generation (RAG) has become a key technique in […]
LMCache: Turboboosting vLLM with 7x faster access to 100x more KV caches
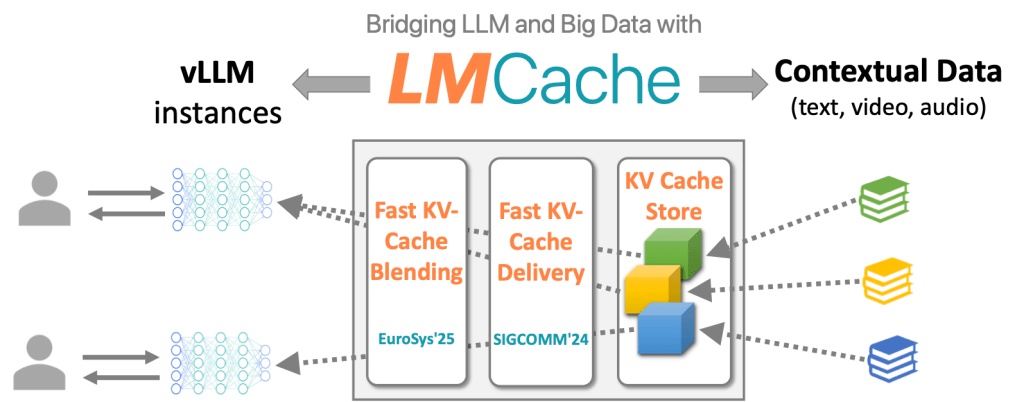
TL;DR: LMCache turboboosts vLLM with 7× faster access to 100x more KV caches, for both multi-turn conversation and RAG . [? Source code] [? Paper1] [? Paper2] [? 3-minute introduction video] LLMs are ubiquitous across industries, but when using them with long documents, it takes forever for the model even to spit […]
