LMCache Lab: Only prefilling? We reduce decoding latency by 60%!
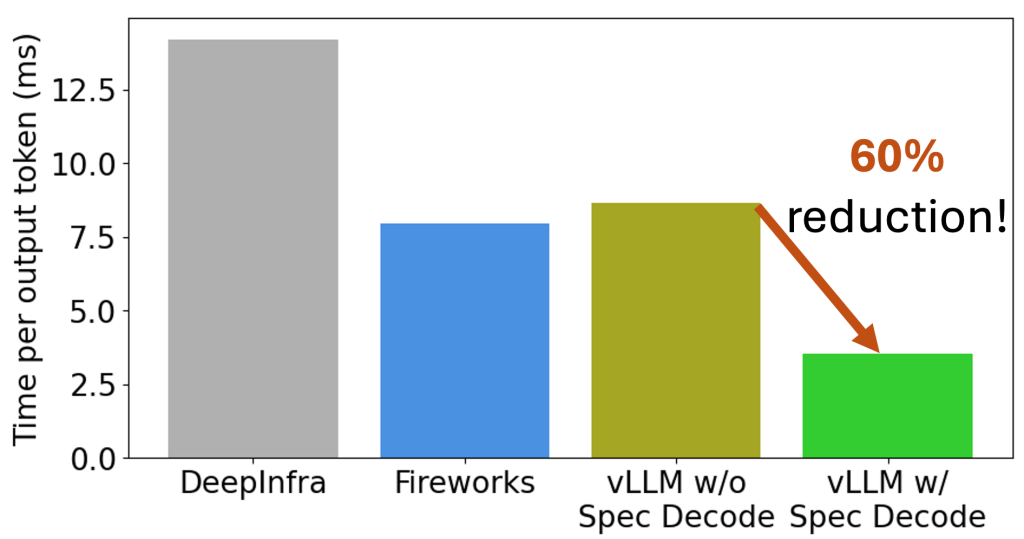
TL;DR: ? LMCache Lab cuts decoding latency for code/text editing by 60% with speculative decoding! ? You might know LMCache Lab for our KV cache optimizations that make LLM prefilling a breeze. But that’s not all! We’re now focused on speeding up decoding too—so your LLM agents can generate new content even faster. In other […]
