LMCache on Amazon SageMaker HyperPod: Accelerating LLM Inference with Managed Tiered KV Cache
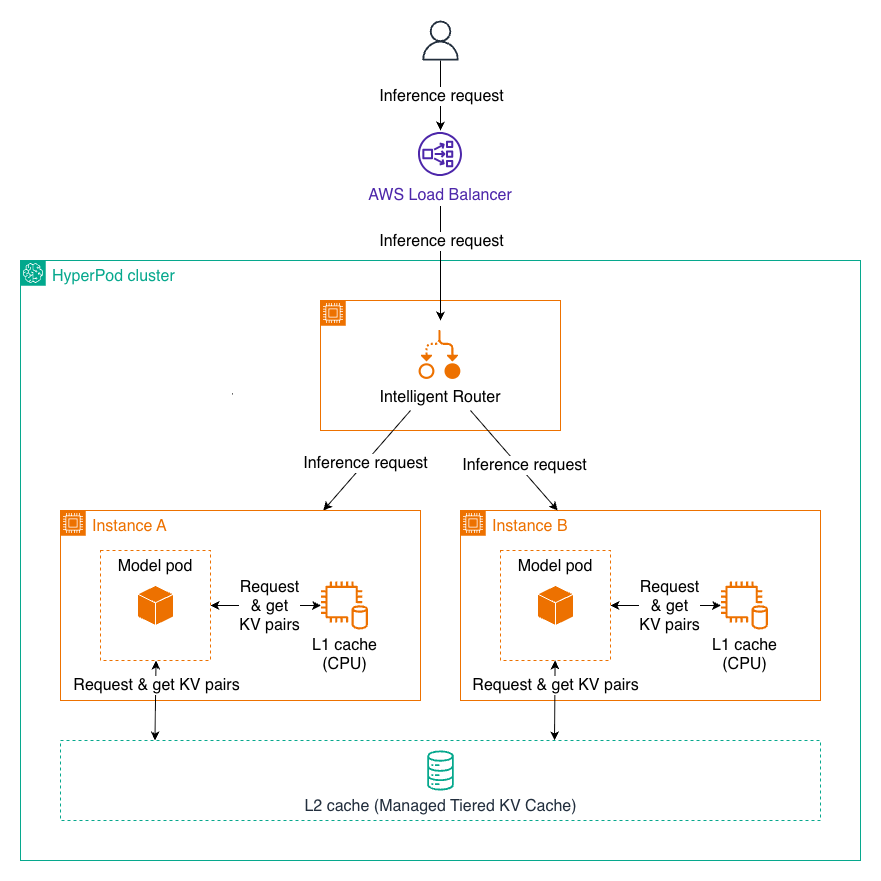
Overview Large language model (LLM) inference performance depends heavily on how efficiently the system manages key-value (KV) cache — the stored attention states that allow the model to avoid recomputing previous tokens. As context lengths grow and concurrent users increase, the KV cache can exceed GPU memory capacity, forcing expensive recomputation that degrades latency and […]
Breaking the Memory Barrier: How LMCache and CoreWeave Power Efficient LLM Inference for Cohere

The challenge: Scaling enterprise AI Enterprises today are racing to integrate large language models (LLMs) into their products and workflows, but doing it at scale brings challenges in performance, cost, and accuracy. Organizations need models to be based on their specific data, while making sure that this information remains private. Cohere, one of the leading […]
LMCache on Google Kubernetes Engine: Boosting LLM Inference Performance with KV Cache on Tiered Storage
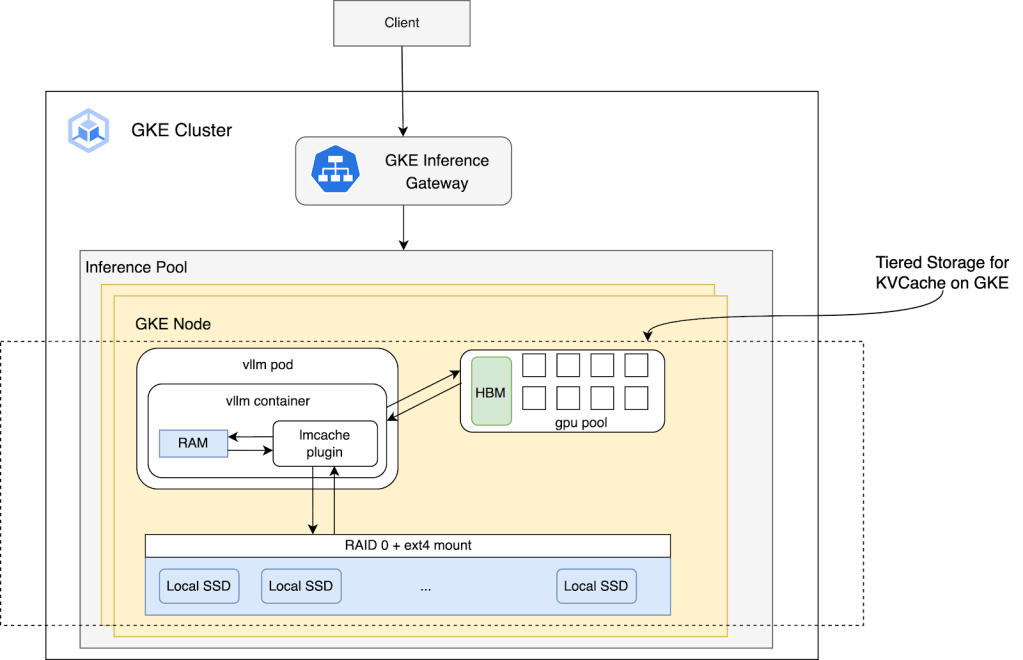
Overview of the Collaboration The KV Cache is a memory optimization that makes Large Language Models(LLMs) run the forward pass faster by storing Key (K) and Value (V) matrices to prevent the model from recalculating them for the entire text sequence with every new generated token. Maximizing the KV Cache hit rate with storage is […]
Extending LMCache Backends: A Comprehensive Guide to Custom Backend Development
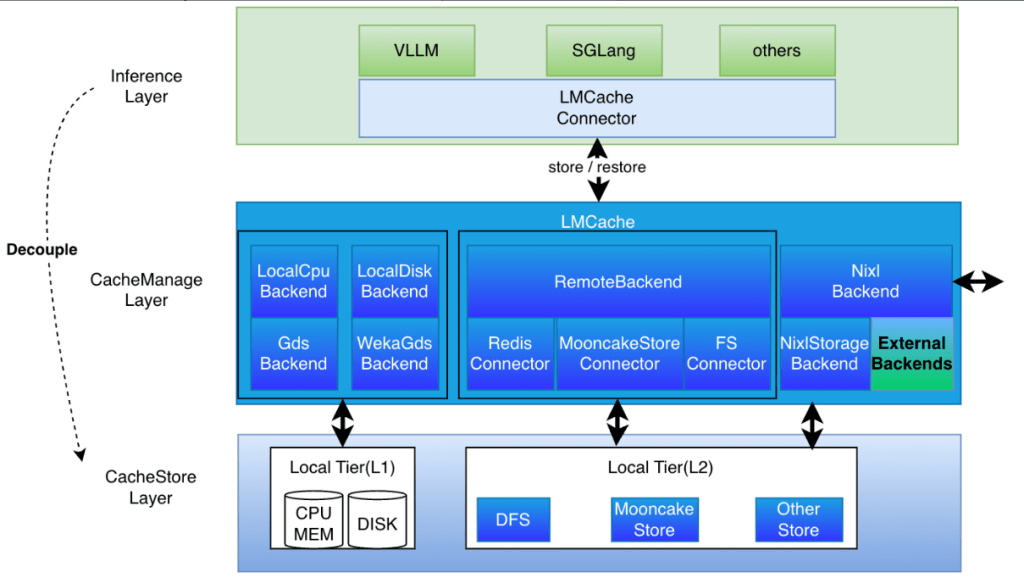
In large language model inference scenarios, the performance and flexibility of KVCache caching systems directly impact overall service efficiency. LMCache, as a high-performance large model caching framework, provides developers with rich extension capabilities through its modular backend design. This article will start with LMCache backend’s extension mechanism, using the officially provided lmc_external_log_backend as an example, […]
CacheGen: Store Your KV Cache on Disk or S3—Load Blazingly Fast!
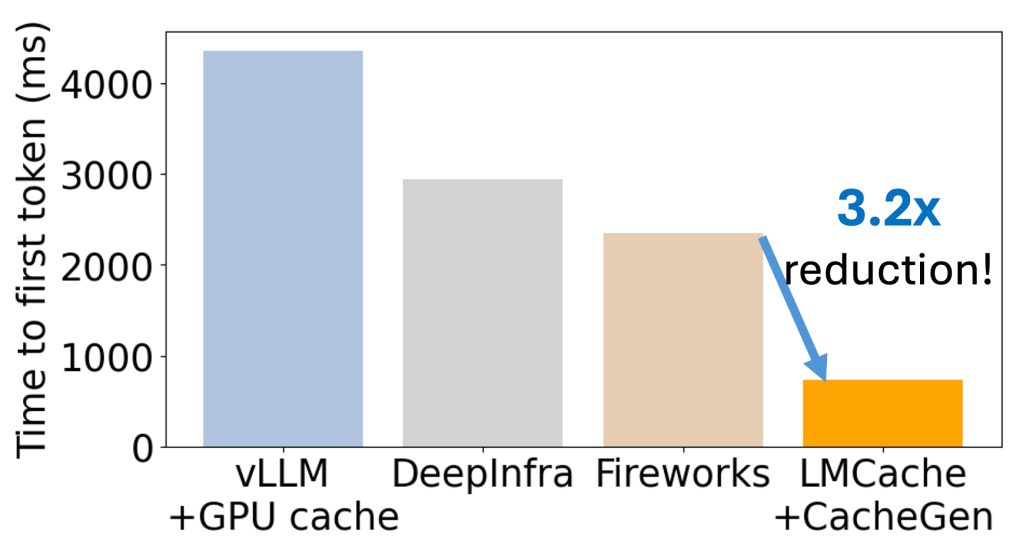
TL;DR: ? CacheGen lets you store KV caches on disk or AWS S3 and load them way faster than recomputing! It compresses your KV cache up to 3× smaller than quantization so that you can load your KV cache blazingly fast while keeping response quality high. Stop wasting compute — use CacheGen to fully utilize […]
LMCache x Mooncake: Unite to Pioneer KVCache-Centric LLM Serving System

Overview of the Collaboration LMCache and Mooncake have announced a strategic collaboration aimed at pioneering a KVCache-centric Large Language Model (LLM) serving system. This partnership seeks to significantly enhance the efficiency, scalability, and responsiveness of LLM applications. By combining LMCache’s advanced KVCache management techniques with Mooncake’s powerful and optimized backend infrastructure, the collaboration aims to […]
