How LMCache Turbocharges Enterprise LLM Inference Frameworks
TL;DR LMCache, the state-of-the-art KV cache layer library developed by TensorMesh and the project’s open-source community, delivers breakthrough performance improvements to modern enterprise LLM inference frameworks, including the vLLM Production Stack, KServe, and NVIDIA’s Dynamo. With fast and scalable caching of long-context KV cache, LMCache helps reduce inference costs and ensures SLOs for both latency […]
Open-Source LLM Inference Cluster Performing 10x FASTER than SOTA OSS Solution
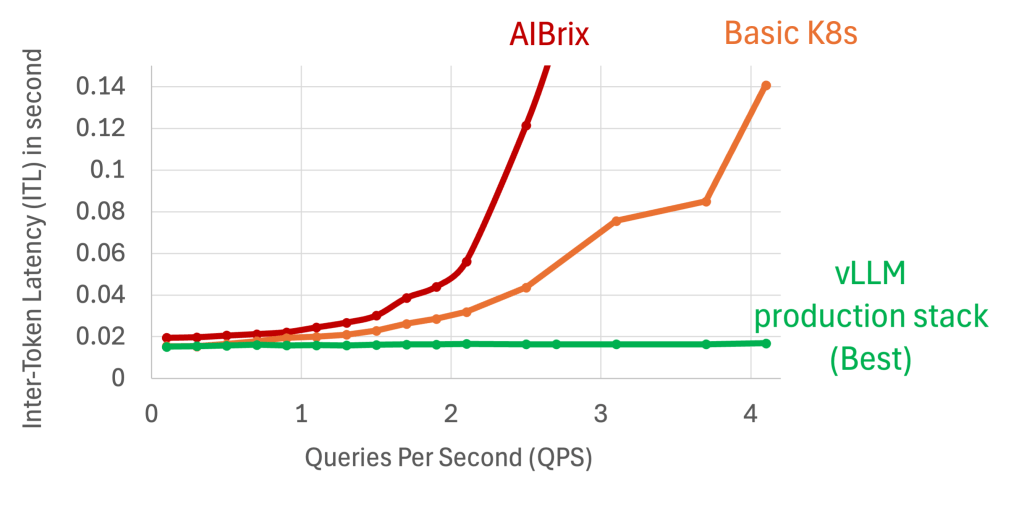
A picture is worth a thousand words: Executive Summary: [vLLM Production Stack Github] | [Get In Touch] | [Slack] | [Linkedin] | [Twitter] Benchmark setups Methods: Workload: Inspired by our production deployments, we create workloads that emulate a typical chat-bot document analysis workload. By default, each LLM query input has 9K tokens, including a document […]
