LMCache on Amazon SageMaker HyperPod: Accelerating LLM Inference with Managed Tiered KV Cache
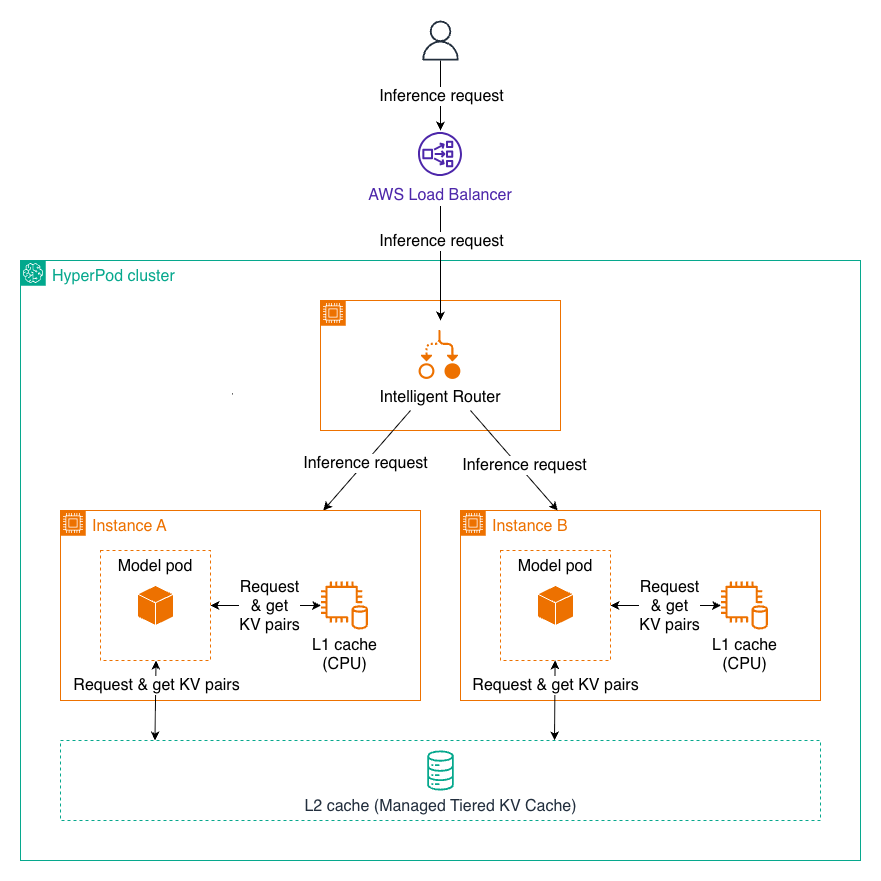
Overview Large language model (LLM) inference performance depends heavily on how efficiently the system manages key-value (KV) cache — the stored attention states that allow the model to avoid recomputing previous tokens. As context lengths grow and concurrent users increase, the KV cache can exceed GPU memory capacity, forcing expensive recomputation that degrades latency and […]
LMCache’s New Architecture Boosts MoE Inference Performance by 10×
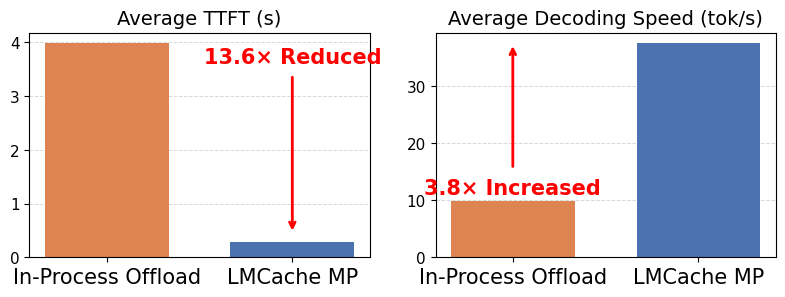
Modern LLM serving workloads are defined by strict latency requirements, high concurrency, and rapidly growing context lengths. Applications such as multi-turn chat, AI agents, and retrieval-augmented generation continuously build on prior context, leading to substantial reuse of previously computed states. In production, systems must minimize time-to-first-token (TTFT) while maintaining stable decoding throughput under heavy concurrent […]
LMCache on Google Kubernetes Engine: Boosting LLM Inference Performance with KV Cache on Tiered Storage
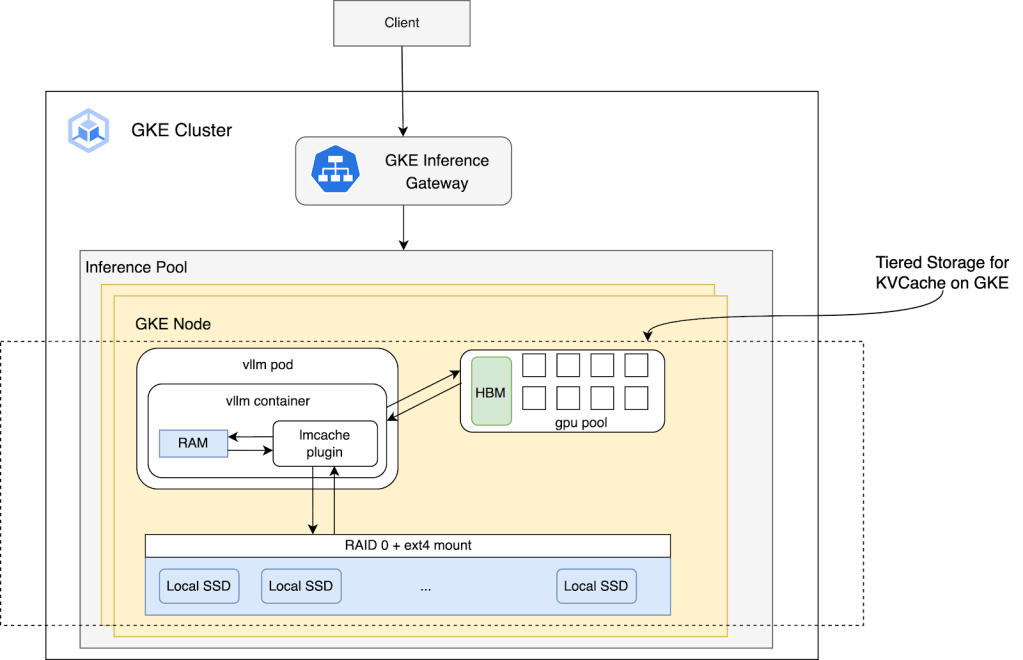
Overview of the Collaboration The KV Cache is a memory optimization that makes Large Language Models(LLMs) run the forward pass faster by storing Key (K) and Value (V) matrices to prevent the model from recalculating them for the entire text sequence with every new generated token. Maximizing the KV Cache hit rate with storage is […]
Implementing LMCache Plugin Framework & lmcache_frontend: Design Philosophy
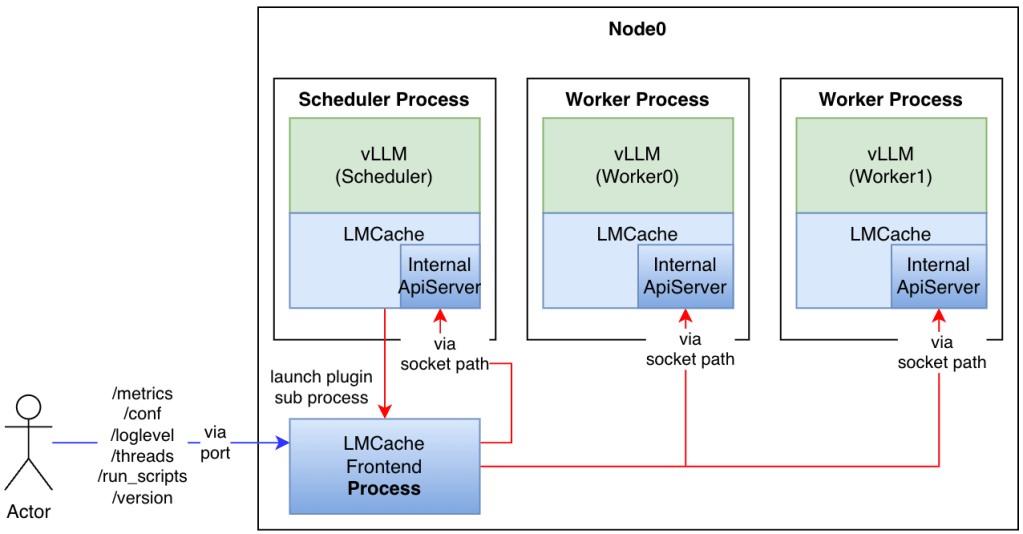
A flexible plugin system for enhanced observability and management Abstract In large-scale language model inference scenarios, efficient memory management and KV cache optimization are crucial. LMCache, as a KV cache management system specifically designed for vLLM, requires more flexible extension mechanisms to meet the needs of monitoring, troubleshooting, and state insight when facing complex production […]
NVIDIA Dynamo integrates LMCache, Accelerating LLM Inference

We’re thrilled to announce that Nvidia Dynamo has integrated LMCache as a KV caching layer solution. This is a big milestone: Dynamo gets a battle-tested caching solution, and LMCache becomes part of a data center-scale inference platform used by many developers worldwide to deploy AI at scale. For comprehensive details about Dynamo’s KV cache optimization […]
LMCache supports gpt-oss (20B/120B) on Day 1
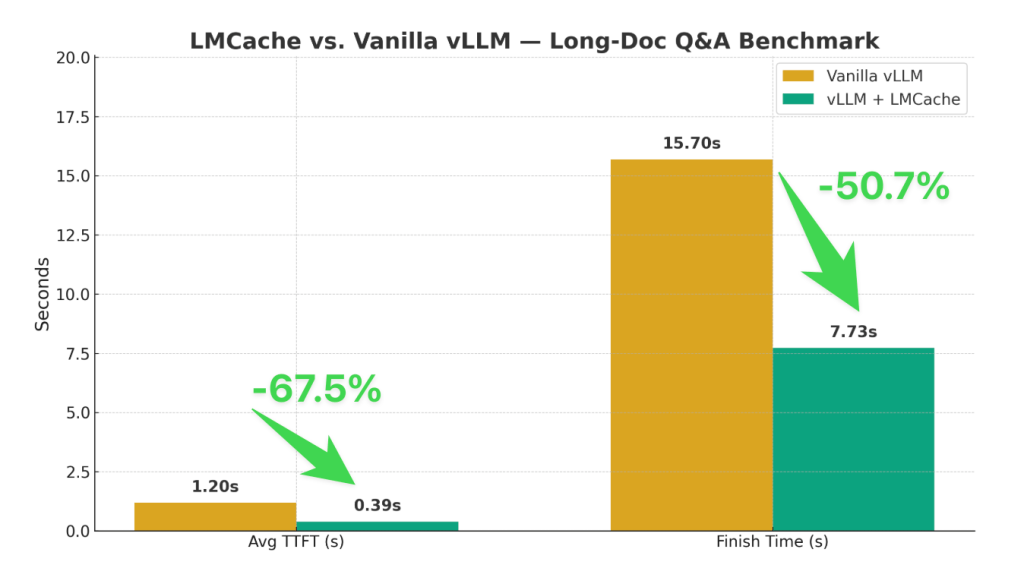
LMCache now supports OpenAI’s newly released GPT-OSS models (20B and 120B parameters) from day one! This post provides a complete guide to setting up vLLM with LMCache for GPT-OSS models and demonstrates significant performance improvements through our CPU offloading capabilities. Step 1: Installing vLLM GPT OSS Version Installation Test the Installation Step 2: Install LMCache […]
Shaping NIXL-based PD Disaggregation in vLLM V1
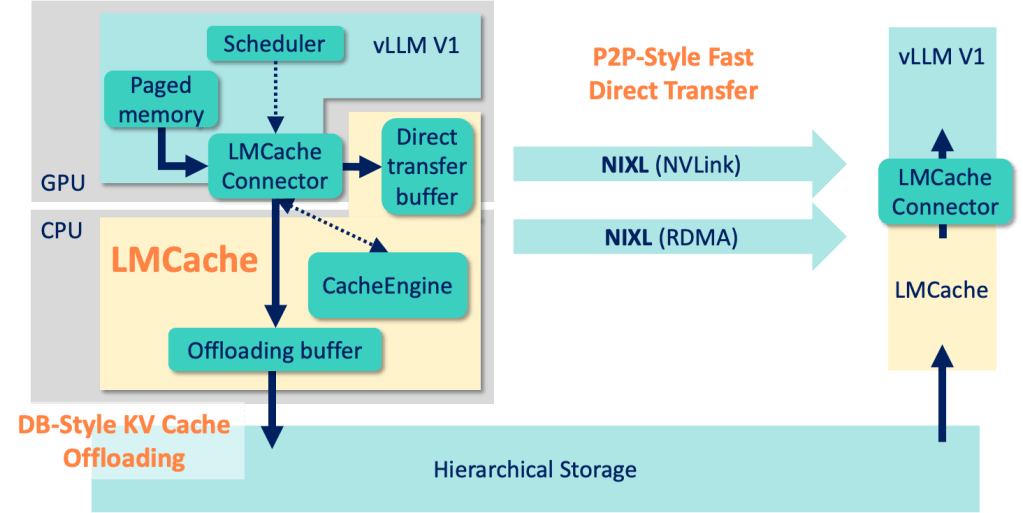
Highlights: Today, LMCache shares two key designs in LLM infrastructure for disaggregated prefill and more: Together, these updates mark a pivotal leap forward in PD disaggregation for vLLM, towards better system flexibility and multi-node scale-out capabilities. A high-level architecture diagram of “vLLM V1 + NIXL + LMCache” integration: vLLM V1 Gets a Major Upgrade with […]
Open-Source LLM Inference Cluster Performing 10x FASTER than SOTA OSS Solution
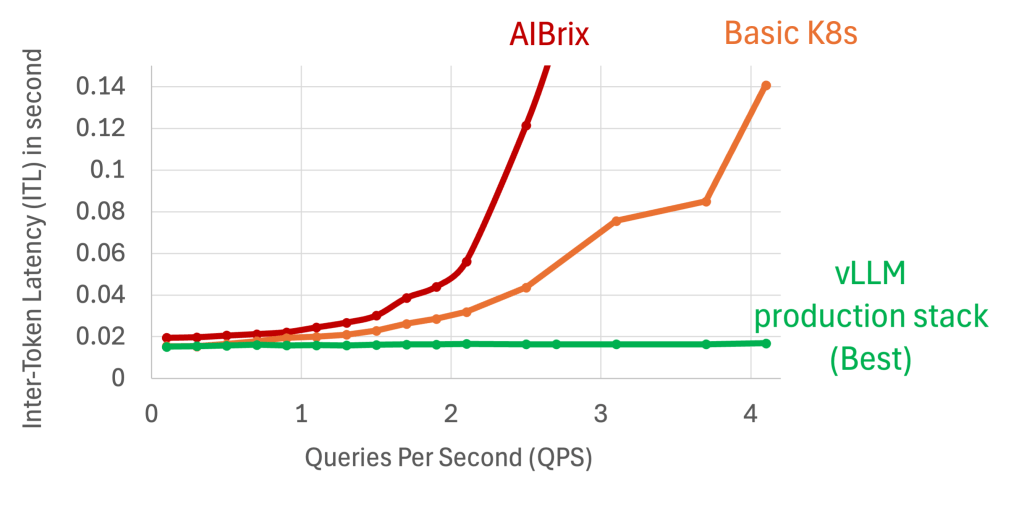
A picture is worth a thousand words: Executive Summary: [vLLM Production Stack Github] | [Get In Touch] | [Slack] | [Linkedin] | [Twitter] Benchmark setups Methods: Workload: Inspired by our production deployments, we create workloads that emulate a typical chat-bot document analysis workload. By default, each LLM query input has 9K tokens, including a document […]
AGI Infra for All: vLLM Production Stack as the Standard for Scalable vLLM Serving

TL;DR Why vLLM Production Stack? AGI isn’t just about better models–it is also about better systems to serve the models to the wide public so that everyone will have access to the new capabilities! In order to fully harness the power of Generative AI, every organization that take this AI revolution seriously needs to have […]
Deploying LLMs in Clusters #2: running “vLLM production-stack” on AWS EKS and GCP GKE
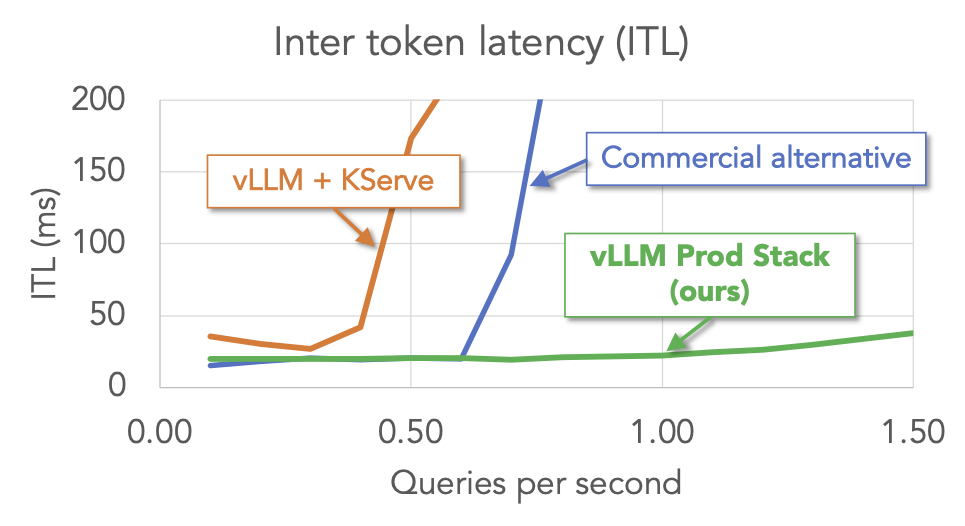
TL;DR [Github Link] | [More Tutorials] | [Get In Touch] AWS Tutorial (click here) GKE Tutorial (click here) The Context vLLM has taken the open-source community by storm, with unparalleled hardware and model support plus an active ecosystem of top-notch contributors. But until now, vLLM has mostly focused on single-node deployments. vLLM Production-stack is an […]
