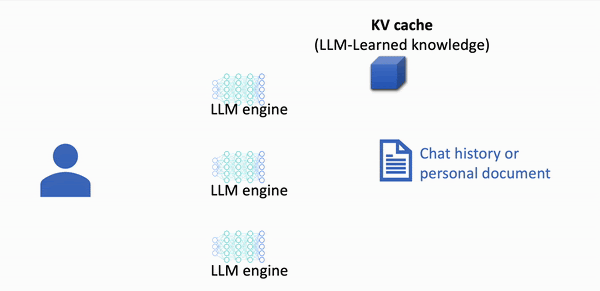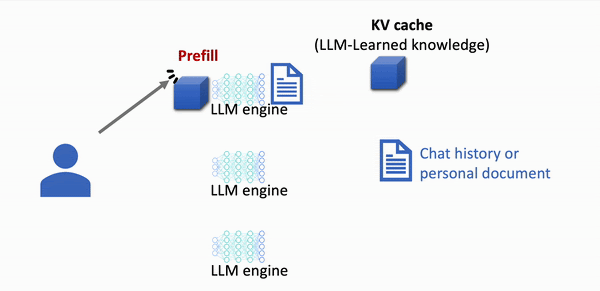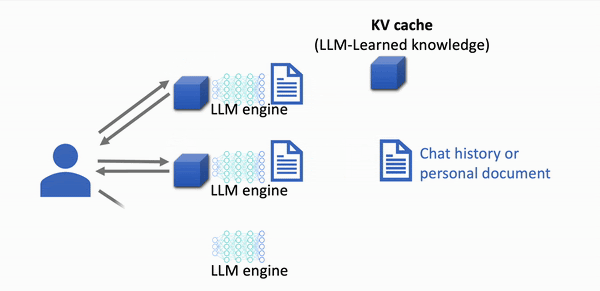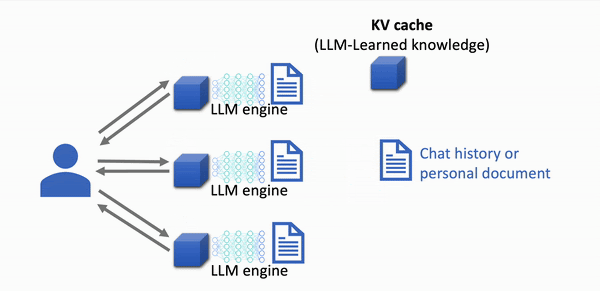
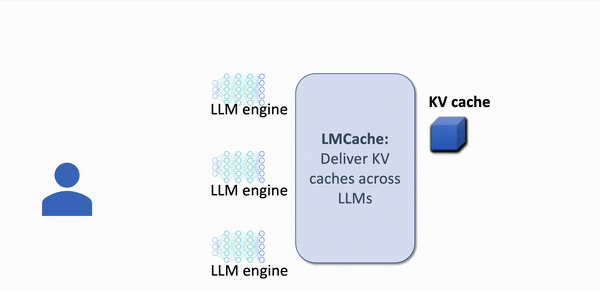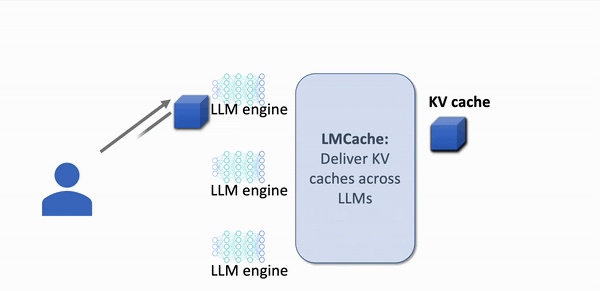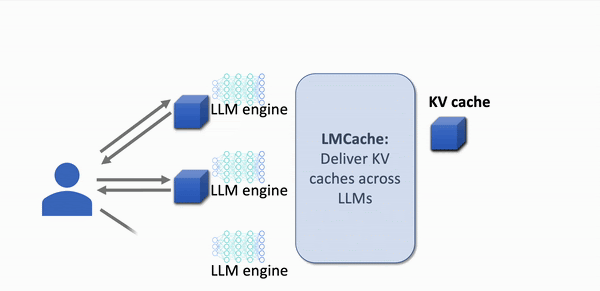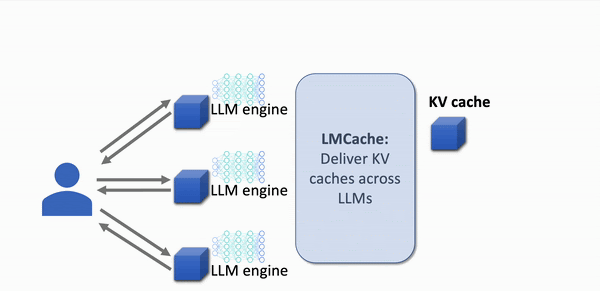
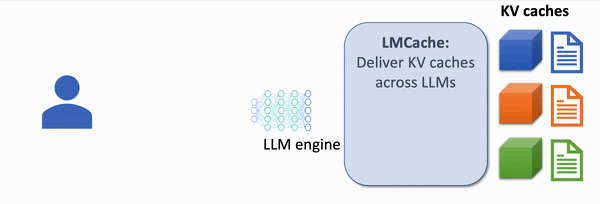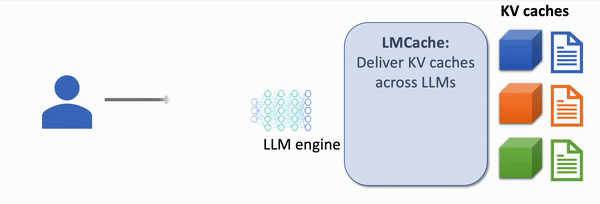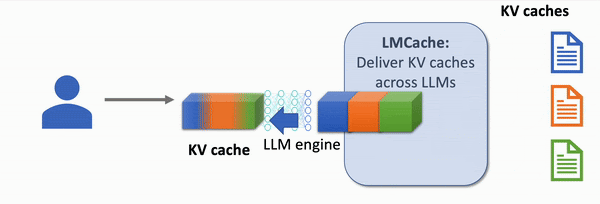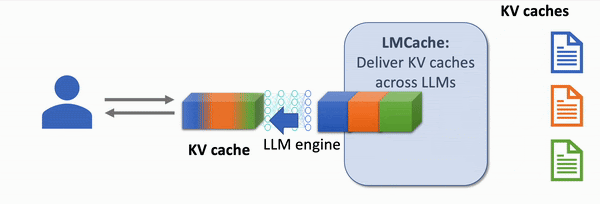
The first open-source Knowledge Delivery Network (KDN) that accelerates LLM applications up to 8x faster, at 8x lower cost.
Without LMCache: Slow Response
With LMCache: 8-10x Faster Response

Without LMCache: Slow Response
With LMCache: 4-10x Faster Response
Authors: Yihua Cheng, Yuhan Liu, Jiayi Yao, Yuwei An, Xiaokun Chen, Shaoting Feng, Yuyang Huang, Samuel Shen, Kuntai Du, Junchen Jiang

Authors: Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Ananthanarayanan, Michael Maire, Henry Hoffmann, Ari Holtzman, Junchen Jiang

Authors: Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, Junchen Jiang

LMCache scales effortlessly, eliminating the need for complex GPU request routing.
Our novel compression techniques reduce the cost of storing and delivering KV caches.
Our unique streaming and decompression methods minimize latency, ensuring fast responses.
Seamless integration with popular LLM serving engines like vLLM and TGI.
LMCache enhances the quality of LLM inferences through offline content upgrades.