LMCache on Amazon SageMaker HyperPod: Accelerating LLM Inference with Managed Tiered KV Cache
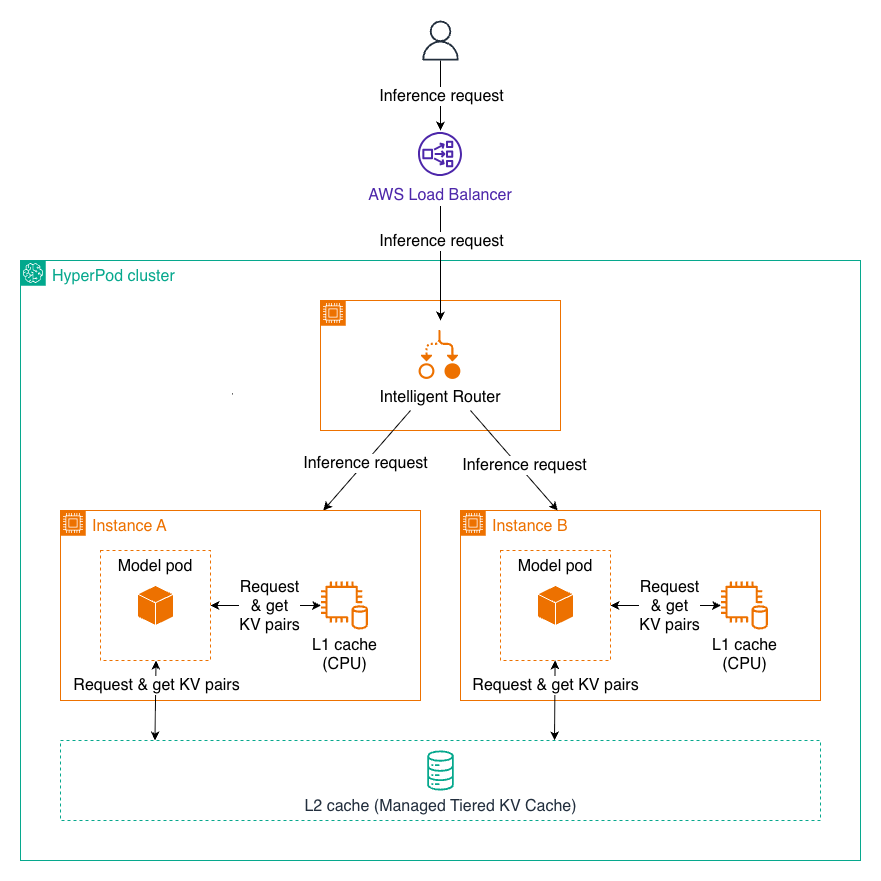
Overview Large language model (LLM) inference performance depends heavily on how efficiently the system manages key-value (KV) cache — the stored attention states that allow the model to avoid recomputing previous tokens. As context lengths grow and concurrent users increase, the KV cache can exceed GPU memory capacity, forcing expensive recomputation that degrades latency and […]
LMCache’s New Architecture Boosts MoE Inference Performance by 10×
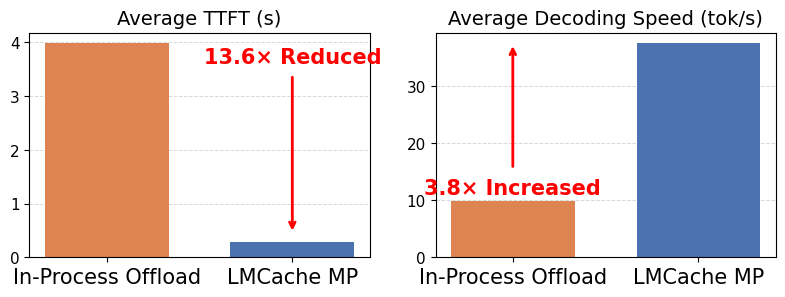
Modern LLM serving workloads are defined by strict latency requirements, high concurrency, and rapidly growing context lengths. Applications such as multi-turn chat, AI agents, and retrieval-augmented generation continuously build on prior context, leading to substantial reuse of previously computed states. In production, systems must minimize time-to-first-token (TTFT) while maintaining stable decoding throughput under heavy concurrent […]
AMD × LMcache: AMD GPU Acceleration with LMcache

Introduction LLM inference becomes increasingly challenging as context length grows and workloads scale. Traditional serving engines rely on prefix-based KV cache reuse, which limits opportunities for optimization, especially when processing long, repeated, or overlapping text across different requests. LMCache addresses this challenge. It is an extension to LLM serving engines that dramatically reduces time-to-first-token (TTFT) […]
Context Engineering & Reuse Pattern Under the Hood of Claude Code
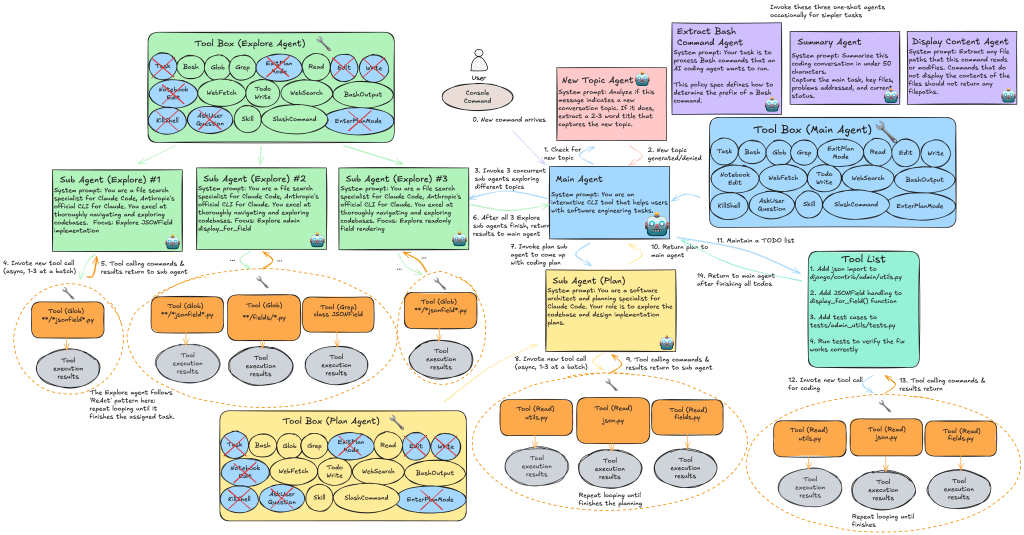
Over the last few months, Claude Code has quietly become one of the most interesting & widely-adopted real-world agentic systems available to normal developers. Unlike cloud-only agents whose internals remain hidden behind API gateways like Perplexity, Devin, or Manus, nor as fully open source agents like Mini SWE Agent or Terminus 2 where you can […]
Breaking the Memory Barrier: How LMCache and CoreWeave Power Efficient LLM Inference for Cohere

The challenge: Scaling enterprise AI Enterprises today are racing to integrate large language models (LLMs) into their products and workflows, but doing it at scale brings challenges in performance, cost, and accuracy. Organizations need models to be based on their specific data, while making sure that this information remains private. Cohere, one of the leading […]
LMCache on Google Kubernetes Engine: Boosting LLM Inference Performance with KV Cache on Tiered Storage
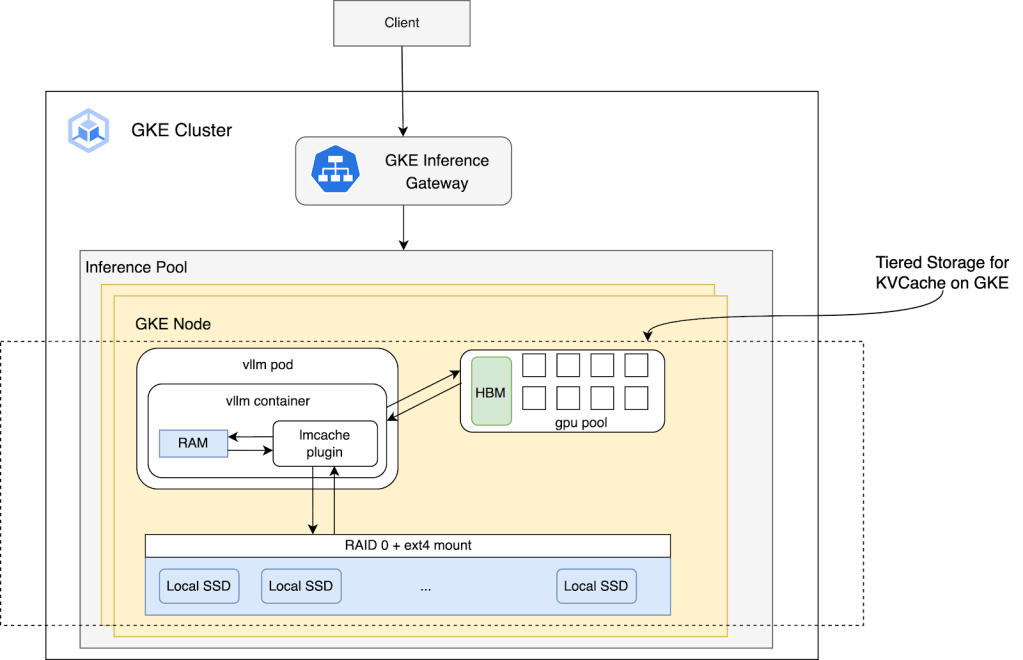
Overview of the Collaboration The KV Cache is a memory optimization that makes Large Language Models(LLMs) run the forward pass faster by storing Key (K) and Value (V) matrices to prevent the model from recalculating them for the entire text sequence with every new generated token. Maximizing the KV Cache hit rate with storage is […]
LMCache supports gpt-oss (20B/120B) on Day 1
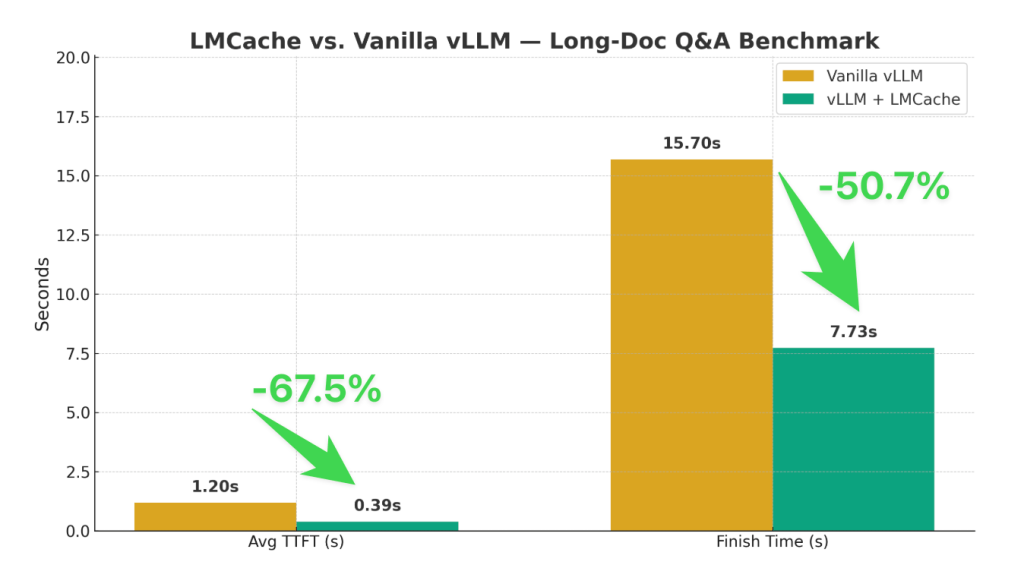
LMCache now supports OpenAI’s newly released GPT-OSS models (20B and 120B parameters) from day one! This post provides a complete guide to setting up vLLM with LMCache for GPT-OSS models and demonstrates significant performance improvements through our CPU offloading capabilities. Step 1: Installing vLLM GPT OSS Version Installation Test the Installation Step 2: Install LMCache […]
Shortest Prefill First—Smarter Scheduling for Faster Prefill!
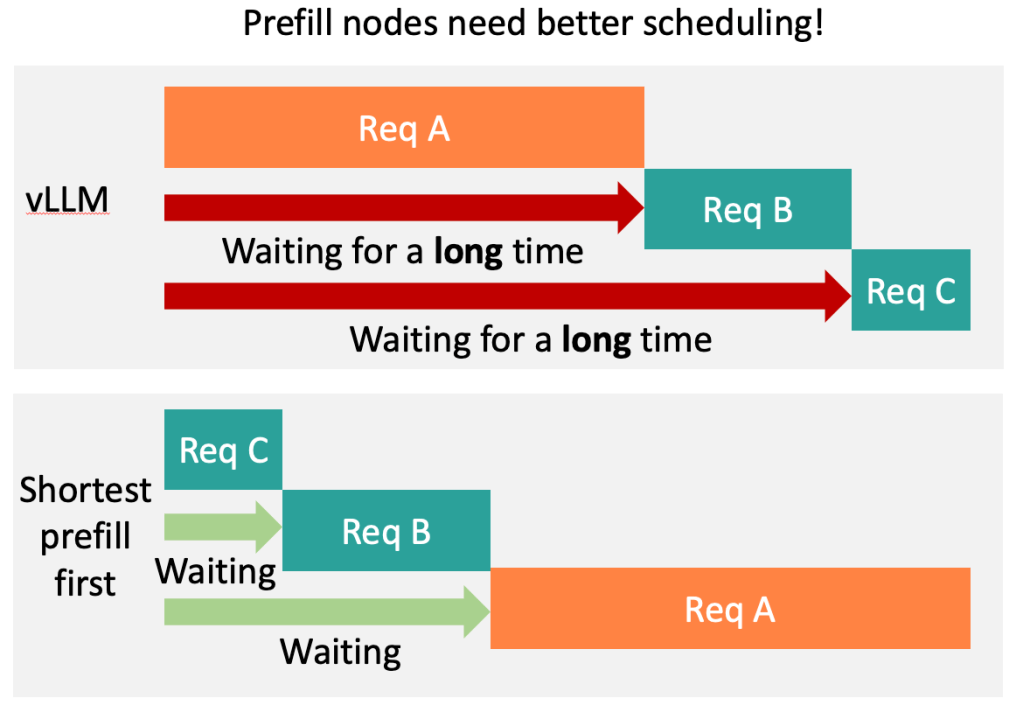
TL;DR: ? Shortest Prefill First (SPF) scheduling cuts LLM time-to-first-token by up to 18% in prefill-decode disaggregation—unlocking even greater gains when combined with LMCache! At LMCache Lab, we’re obsessed with LLM performance. As prefill-decode disaggregation becomes the norm, we spotted a major, untapped scheduling opportunity for prefill nodes.That’s why we developed SPF (Shortest Prefill First, […]
LMCache Lab: Only prefilling? We reduce decoding latency by 60%!
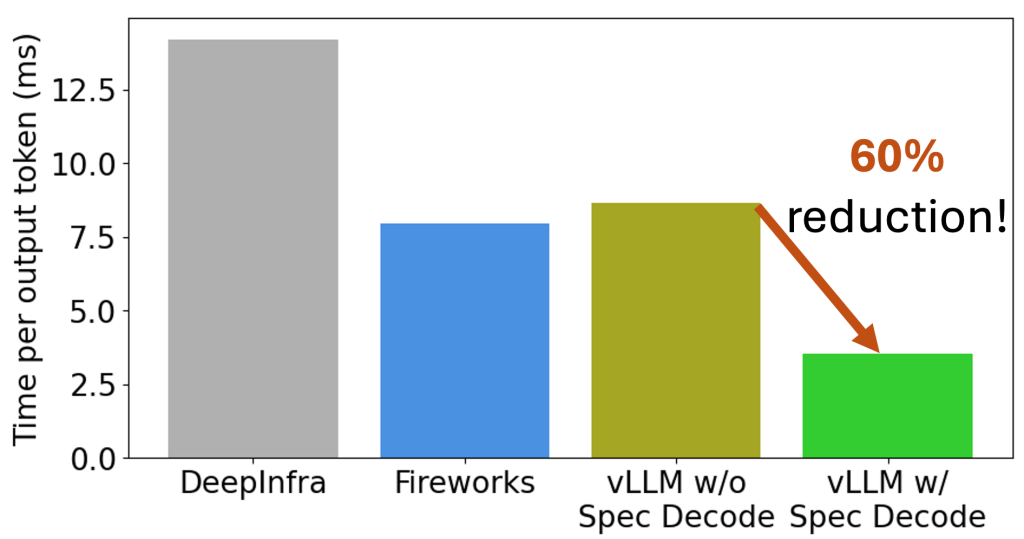
TL;DR: ? LMCache Lab cuts decoding latency for code/text editing by 60% with speculative decoding! ? You might know LMCache Lab for our KV cache optimizations that make LLM prefilling a breeze. But that’s not all! We’re now focused on speeding up decoding too—so your LLM agents can generate new content even faster. In other […]
Bringing State-Of-The-Art PD Speed to vLLM v1 with LMCache
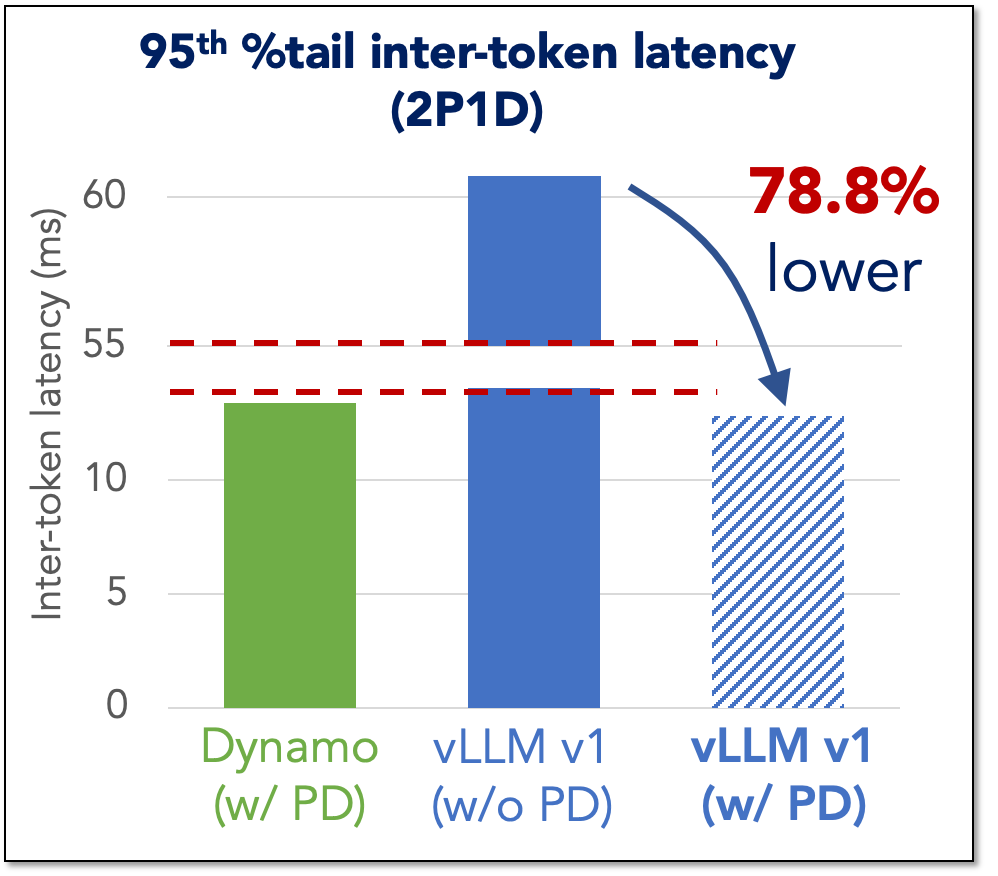
TL;DR:In our previous blog, we introduced **LMCache**’s integration with vLLM v1 and NVIDIA’s NIXL used in Dynamo, enabling Prefill-Decode Disaggregation (PD) for LLM inference. Today, we’re excited to share benchmark results that confirm this system achieves state-of-the-art PD performance, balancing time-to-first-token (TTFT) and inter-token latency (ITL) with unprecedented consistency. Here’s an example result (scroll down […]
