TL;DR: ? Shortest Prefill First (SPF) scheduling cuts LLM time-to-first-token by up to 18% in prefill-decode disaggregation—unlocking even greater gains when combined with LMCache!
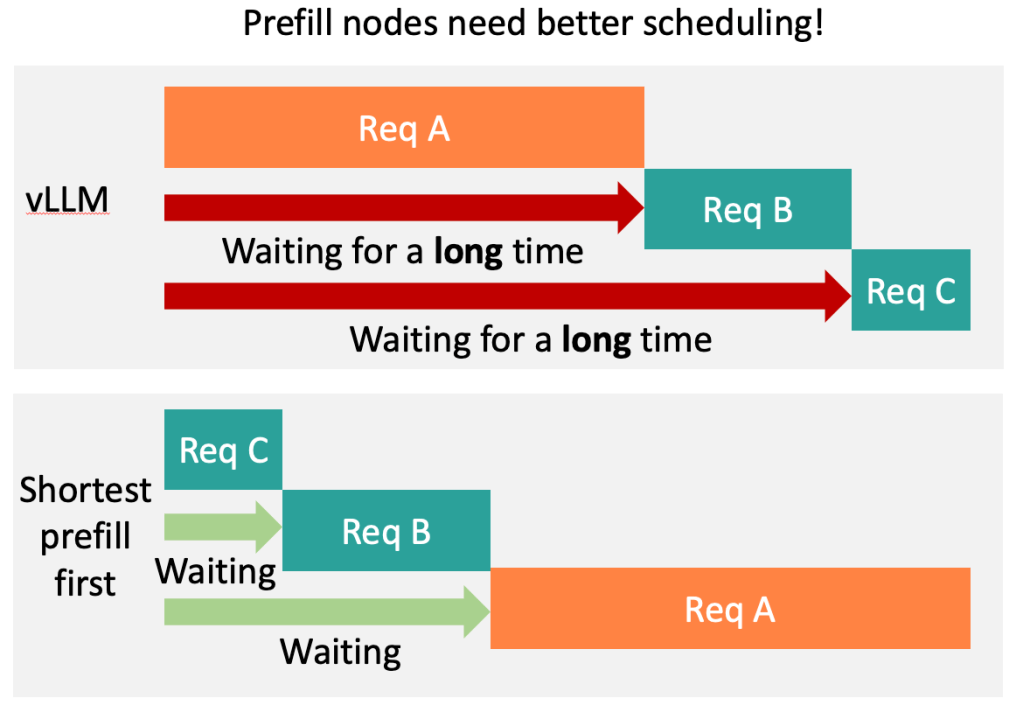
At LMCache Lab, we’re obsessed with LLM performance. As prefill-decode disaggregation becomes the norm, we spotted a major, untapped scheduling opportunity for prefill nodes.
That’s why we developed SPF (Shortest Prefill First, introduced in our SOSP 2025 paper), a scheduling strategy that always serves requests with the shortest prefill time first. This reduces queueing delays across the board and gets your users their results faster.
We’ve implemented a proof-of-concept for SPF in vLLM (PR).
Benchmarking SPF ?
Here’s a side-by-side comparison of mean and median time-to-first-token (TTFT) for leading LLM serving platforms (200 random input lengths averaging 10,000; output length = 1; all requests arriving at once):
| Approach | Mean TTFT (ms) | Median TTFT (ms) |
|---|---|---|
| vLLM (native) | 7,500.75 | 6,280.66 |
| vLLM (SPF) | 6,116.30 | 4,816.27 |
| Fireworks | 8,052.40 | 7,943.03 |
| DeepInfra | 7,664.74 | 6,564.00 |
Takeaway:
Shortest Prefill First delivers an 18% reduction in mean TTFT compared to native vLLM, with even larger gains over Fireworks and DeepInfra. The median TTFT improvements are just as strong—SPF consistently delivers faster results from your hardware!
SPF unlocks even more with LMCache ?
The real power of SPF emerges when paired with an advanced KV cache layer.
SPF boosts your KV cache hit rate by enhancing cache locality—requests that benefit most from the cache (and thus have shorter prefill times) are prioritized. To maximize the benefits, SPF and the KV cache system should work hand-in-hand.
We’re actively integrating SPF with LMCache—the most advanced KV cache layer available—unlocking even more dramatic speedups and cost savings at scale.
Want to try it out? ?
Ready for these speedups out-of-the-box? LMIgnite is your one-click solution for LLM deployment. It’s easy, multi-tenant, and delivers top-tier performance—including SPF and other cutting-edge research—without any engineering hassle.
Sign up here for early access.
Faster prefill, faster decode, more efficient infra—the LMCache Lab way! ?
Contacts
- LMCache Github: https://github.com/LMCache/LMCache
- Chat with the Developers Interest Form
- LMCache slack
- vLLM Production-Stack channel
