LMCache’s New Architecture Boosts MoE Inference Performance by 10×
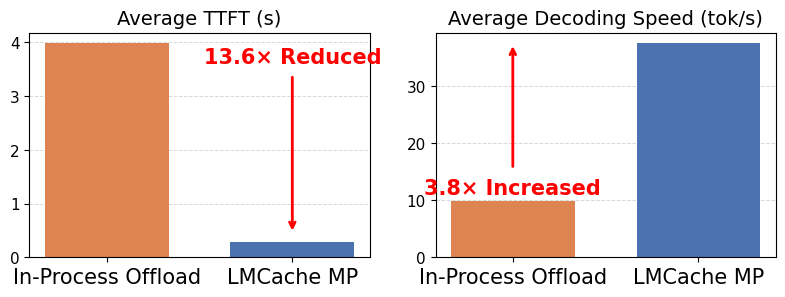
Modern LLM serving workloads are defined by strict latency requirements, high concurrency, and rapidly growing context lengths. Applications such as multi-turn chat, AI agents, and retrieval-augmented generation continuously build on prior context, leading to substantial reuse of previously computed states. In production, systems must minimize time-to-first-token (TTFT) while maintaining stable decoding throughput under heavy concurrent […]
LMCache Multi-node P2P CPU Memory Sharing & Control: From Experimental Feature to Production
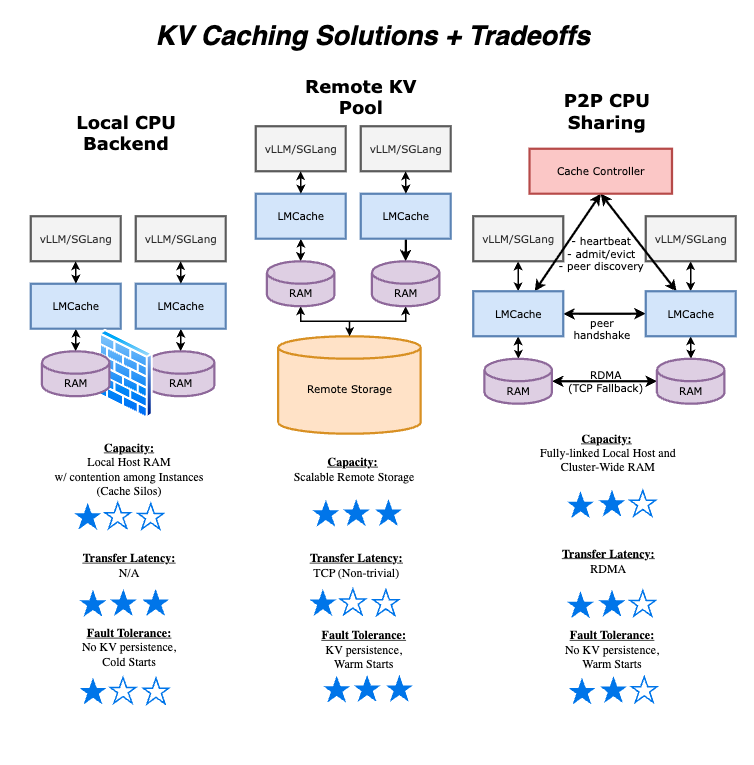
Baolong Mao (Tencent), Chunxiao Zheng (Tencent), Weishu Deng (Tensormesh), Darren Peng (Tensormesh), Samuel Shen (Tensormesh) What is P2P and what does it promise? In this blog post, we will go over: Most production vLLM deployments run multiple identical instances behind a load balancer. Each instance builds its own KV cache only from the traffic it […]
Implementing LMCache Plugin Framework & lmcache_frontend: Design Philosophy
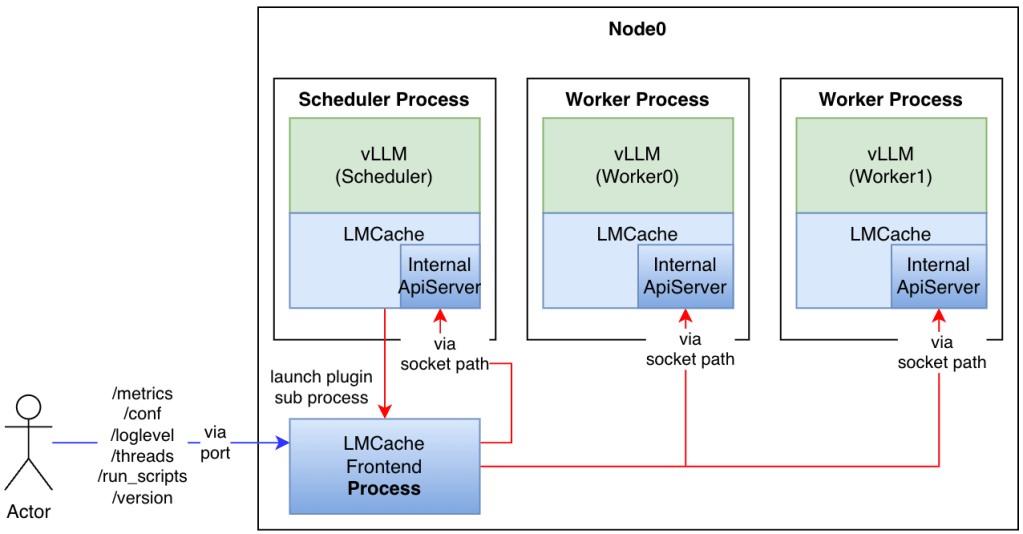
A flexible plugin system for enhanced observability and management Abstract In large-scale language model inference scenarios, efficient memory management and KV cache optimization are crucial. LMCache, as a KV cache management system specifically designed for vLLM, requires more flexible extension mechanisms to meet the needs of monitoring, troubleshooting, and state insight when facing complex production […]
Shortest Prefill First—Smarter Scheduling for Faster Prefill!
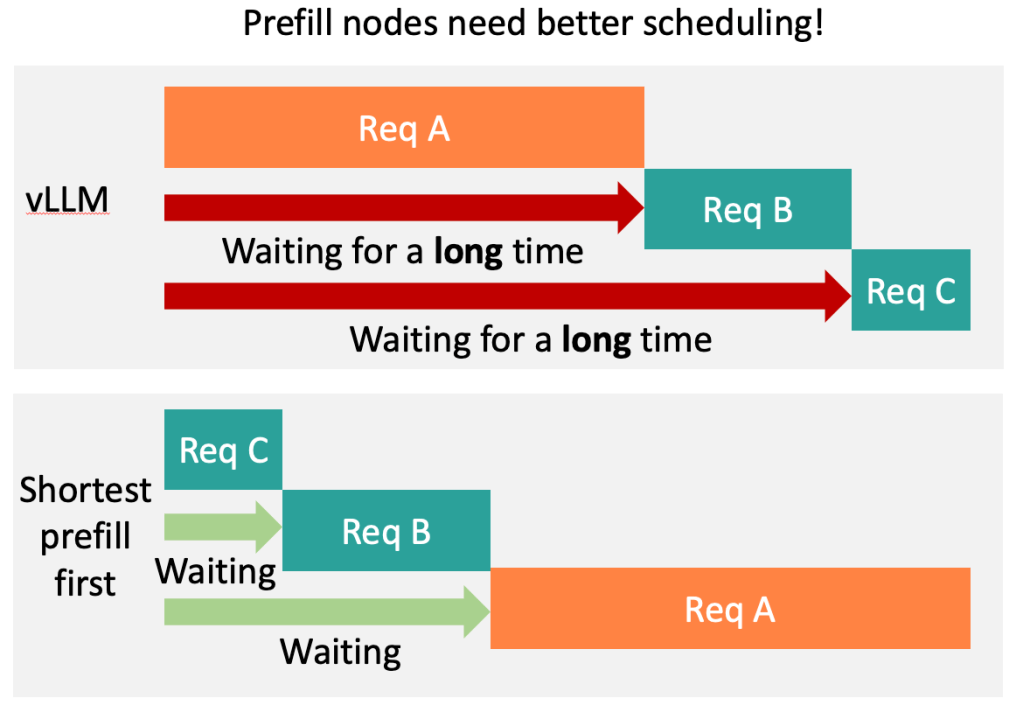
TL;DR: ? Shortest Prefill First (SPF) scheduling cuts LLM time-to-first-token by up to 18% in prefill-decode disaggregation—unlocking even greater gains when combined with LMCache! At LMCache Lab, we’re obsessed with LLM performance. As prefill-decode disaggregation becomes the norm, we spotted a major, untapped scheduling opportunity for prefill nodes.That’s why we developed SPF (Shortest Prefill First, […]
LMIgnite: Fastest LLM Inference for Conversational and Long-Document AI, Only One Click Away
TL;DR: LLMs are transforming every product and service—from chatbots and copilots to intelligent document search and enterprise workflows. But running LLMs in production is still painfully slow, prohibitively expensive, and complex to manage. That changes today. We’re excited to announce the launch of LMIgnite — the first one-click deployable high-performance LLM inference backend for Conversational […]
Speeding Up LLM Inference: Beyond the Inference Engine

TL;DR: LLMs are rapidly becoming the dominant workload in enterprise AI. As more applications rely on real-time generation, inference performance — measured in speed, cost, and reliability — becomes the key bottleneck. Today, the industry focuses primarily on speeding up inference engines like vLLM, SGLang, and TensorRT. But in doing so, we’re overlooking a much […]
LMCache Extends Its Turbo-Boost to Multimodal Models in vLLM V1
TL;DR: The latest LMCache release plugs seamlessly into vLLM’s new multimodal stack. By hashing image-side tokens (mm_hashes) and caching their key-value (KV) pairs, LMCache reuses vision embeddings across requests—slashing time-to-first-token and GPU memory for visual-LLMs. Summary — Why This Matters Multimodal large language models (MLLMs) multiply KV-cache traffic: every image can add thousands of “vision […]
LLM Production Stack Goes Cross-Hardware: Ascend, Arm, and AMD Support Incoming
TL;DR: Our LLM Production Stack project just hit another milestone. We’re integrating with more hardware accelerators — including Ascend, Arm, and AMD — signaling growing maturity and broader applicability across enterprise and research settings. ? LMCache Is Gaining Traction LMCache has quietly become the unsung hero in the LLM inference world. As a core component […]
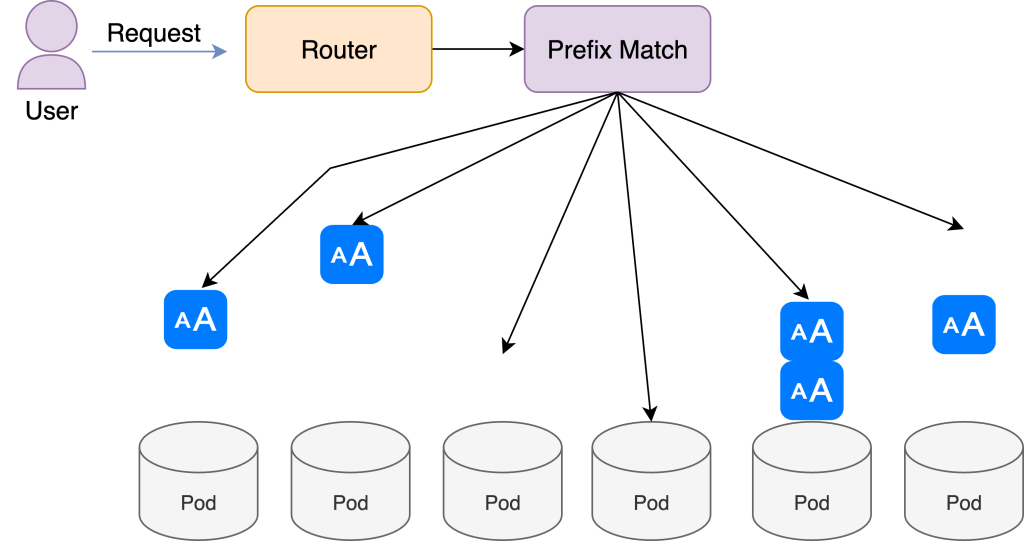
AGI Infra for All: vLLM Production Stack as the Standard for Scalable vLLM Serving

TL;DR Why vLLM Production Stack? AGI isn’t just about better models–it is also about better systems to serve the models to the wide public so that everyone will have access to the new capabilities! In order to fully harness the power of Generative AI, every organization that take this AI revolution seriously needs to have […]
