Shortest Prefill First—Smarter Scheduling for Faster Prefill!
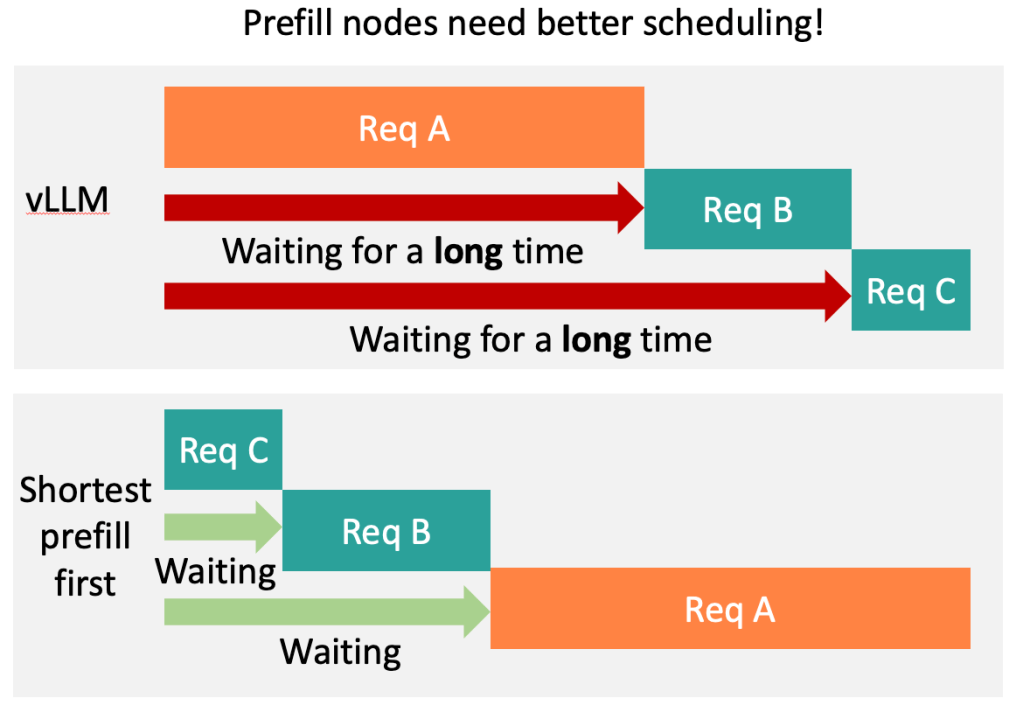
TL;DR: ? Shortest Prefill First (SPF) scheduling cuts LLM time-to-first-token by up to 18% in prefill-decode disaggregation—unlocking even greater gains when combined with LMCache! At LMCache Lab, we’re obsessed with LLM performance. As prefill-decode disaggregation becomes the norm, we spotted a major, untapped scheduling opportunity for prefill nodes.That’s why we developed SPF (Shortest Prefill First, […]
